
در این پست از سایت بنو قصد داریم به بررسی الگوریتم جدیدی که زبان را فقط با تماشای ویدیو کشف میکند، بپردازیم!
آنچه در این مطلب خواهید خواند
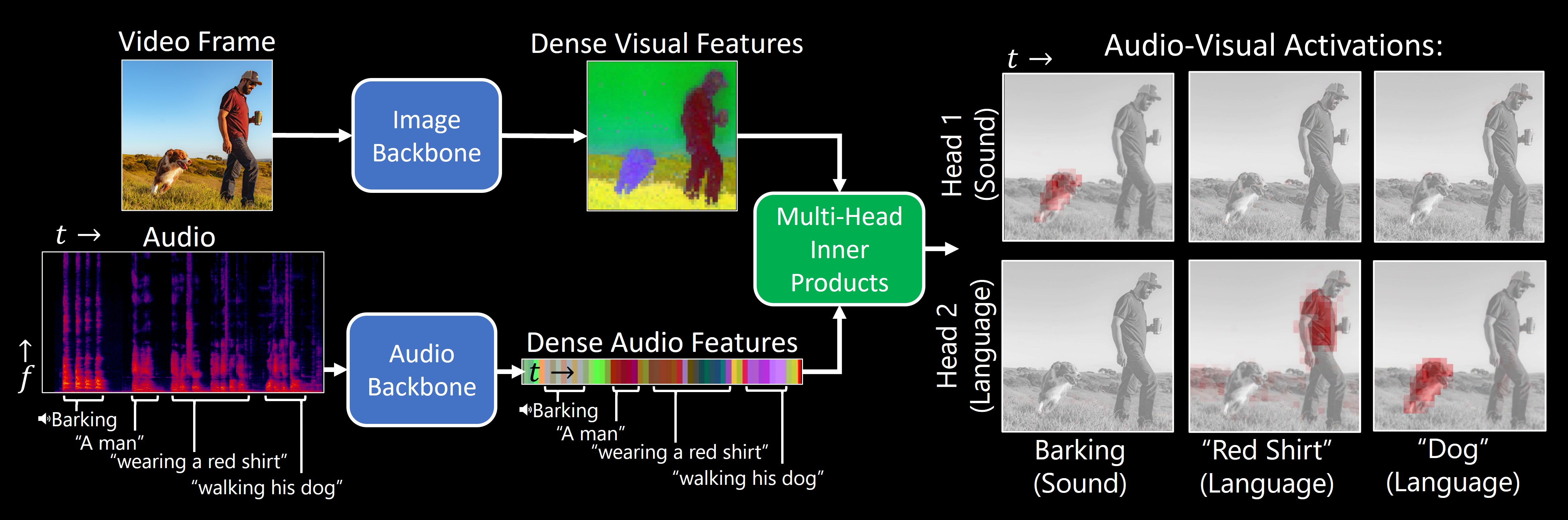
معرفی الگوریتم DenseAV
DenseAV، الگوریتمی که در دانشگاه MIT توسعه داده شده، یاد میگیرد چگونه زبان را تحلیل کند و معنی آن را بفهمد، تنها با تماشای ویدیوهایی که افراد در آن صحبت میکنند. این الگوریتم قابلیتهای بالقوهای در جستجوی چندرسانهای، یادگیری زبان، و رباتیک دارد. مارک همیلتون، دانشجوی دکترای مهندسی برق و علوم کامپیوتر در MIT و یکی از اعضای آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT (CSAIL)، قصد دارد از ماشینها برای درک نحوه ارتباط حیوانات استفاده کند. برای رسیدن به این هدف، او ابتدا تصمیم گرفت سیستمی بسازد که بتواند زبان انسان را “از پایه” یاد بگیرد.
همیلتون میگوید: «اتفاق جالب این بود که لحظهای که الهام بخش ما شد، از فیلم “مارش پنگوئنها” بود. در یکی از صحنهها، پنگوئنی روی یخ میافتد و در حالی که بلند میشود، یک ناله کوچک میزند. وقتی آن را میبینید، تقریباً واضح است که این ناله مثل جایگزینی برای یک کلمه چهار حرفی است. در آن لحظه فکر کردیم، شاید باید از صدا و تصویر برای یادگیری زبان استفاده کنیم. آیا راهی وجود دارد که بتوانیم به یک الگوریتم اجازه دهیم تمام روز تلویزیون تماشا کند و از این طریق بفهمد داریم درباره چه صحبت میکنیم؟»
او اضافه میکند: «مدل ما، DenseAV، هدفش این است که با پیشبینی آنچه که میبیند از آنچه میشنود، و بالعکس، زبان را یاد بگیرد. برای مثال، اگر صدای کسی را بشنوید که میگوید “کیک را با دمای ۳۵۰ درجه بپز”، احتمالاً کیک یا یک فر را در تصویر خواهید دید. برای موفقیت در این بازی تطبیق صوت و تصویر با میلیونها ویدیو، مدل باید یاد بگیرد که افراد درباره چه صحبت میکنند.»
پس از آموزش DenseAV در این بازی تطبیق، همیلتون و همکارانش به این موضوع پرداختند که مدل وقتی صدایی را میشنود، به کدام پیکسلها نگاه میکند. برای مثال، وقتی کسی میگوید «سگ»، الگوریتم بلافاصله شروع به جستجو برای سگ در جریان ویدیو میکند. با دیدن پیکسلهایی که توسط الگوریتم انتخاب میشوند، میتوان فهمید که الگوریتم فکر میکند یک کلمه به چه معنی است.

چگونگی عملکرد DenseAV
جالب اینجاست که یک فرآیند جستجوی مشابه وقتی اتفاق میافتد که DenseAV صدای پارس سگ را میشنود: الگوریتم به دنبال سگ در جریان ویدیو میگردد. همیلتون میگوید: «این مسئله توجه ما را جلب کرد. میخواستیم بدانیم آیا الگوریتم تفاوت بین کلمه “سگ” و صدای پارس سگ را میداند یا نه.» تیم برای بررسی این موضوع به DenseAV یک “مغز دو طرفه” دادند. جالب اینجاست که آنها متوجه شدند یک سمت مغز DenseAV بهطور طبیعی روی زبان متمرکز است، مثل کلمه “سگ”، و سمت دیگر روی صداها مثل صدای پارس تمرکز دارد. این نشان داد که DenseAV نه تنها معنی کلمات و مکانهای صداها را یاد گرفته، بلکه توانسته بین این نوع ارتباطات چندحسی تفاوت قائل شود، آن هم بدون دخالت انسان یا آگاهی از زبان نوشتاری.
یکی از شاخههای کاربرد این الگوریتم، یادگیری از حجم وسیعی از ویدیوهایی است که هر روز به اینترنت منتشر میشود. همیلتون میگوید: «ما میخواهیم سیستمهایی بسازیم که بتوانند از حجم عظیمی از محتوای ویدیویی، مانند ویدیوهای آموزشی، یاد بگیرند. یکی دیگر از کاربردهای هیجانانگیز این است که بتوانیم زبانهای جدیدی مانند ارتباطات دلفینها یا نهنگها را که فرم نوشتاری ندارند، درک کنیم. امید ما این است که DenseAV بتواند به ما در درک این زبانها که از ابتدای تاریخ تلاشهای انسانی برای ترجمهشان شکست خورده، کمک کند. نهایتاً، امیدواریم که این روش بتواند الگوهایی بین دیگر سیگنالها مانند صداهای لرزهای زمین و زمینشناسی آن را کشف کند.»
چالش بزرگی پیش روی تیم بود: یادگیری زبان بدون هیچگونه ورودی متنی. هدف آنها این بود که معنی زبان را از ابتدا کشف کنند، بدون استفاده از مدلهای زبانی از پیش آموزشدیده. این رویکرد الهام گرفته از نحوه یادگیری کودکان است که با مشاهده و شنیدن محیط اطرافشان زبان را میفهمند.
برای دستیابی به این هدف، DenseAV از دو مؤلفه اصلی برای پردازش دادههای صوتی و تصویری به طور جداگانه استفاده میکند. این جداسازی باعث شد که الگوریتم نتواند تقلب کند؛ یعنی مثلاً بخش تصویری به صدا ها نگاه کند یا بالعکس. این روش الگوریتم را مجبور کرد که اشیا را بشناسد و ویژگیهای دقیق و معناداری برای سیگنالهای صوتی و تصویری ایجاد کند. DenseAV با مقایسه جفتهای سیگنالهای صوتی و تصویری یاد میگیرد که کدام سیگنالها با هم تطابق دارند و کدام ندارند. این روش که به “یادگیری تضادآمیز” معروف است، نیازی به نمونههای برچسبگذاری شده ندارد و به DenseAV اجازه میدهد خودش الگوهای پیشبینیکننده مهم زبان را کشف کند.
برتری DenseAV نسبت به سایر الگوریتم های تشخیص
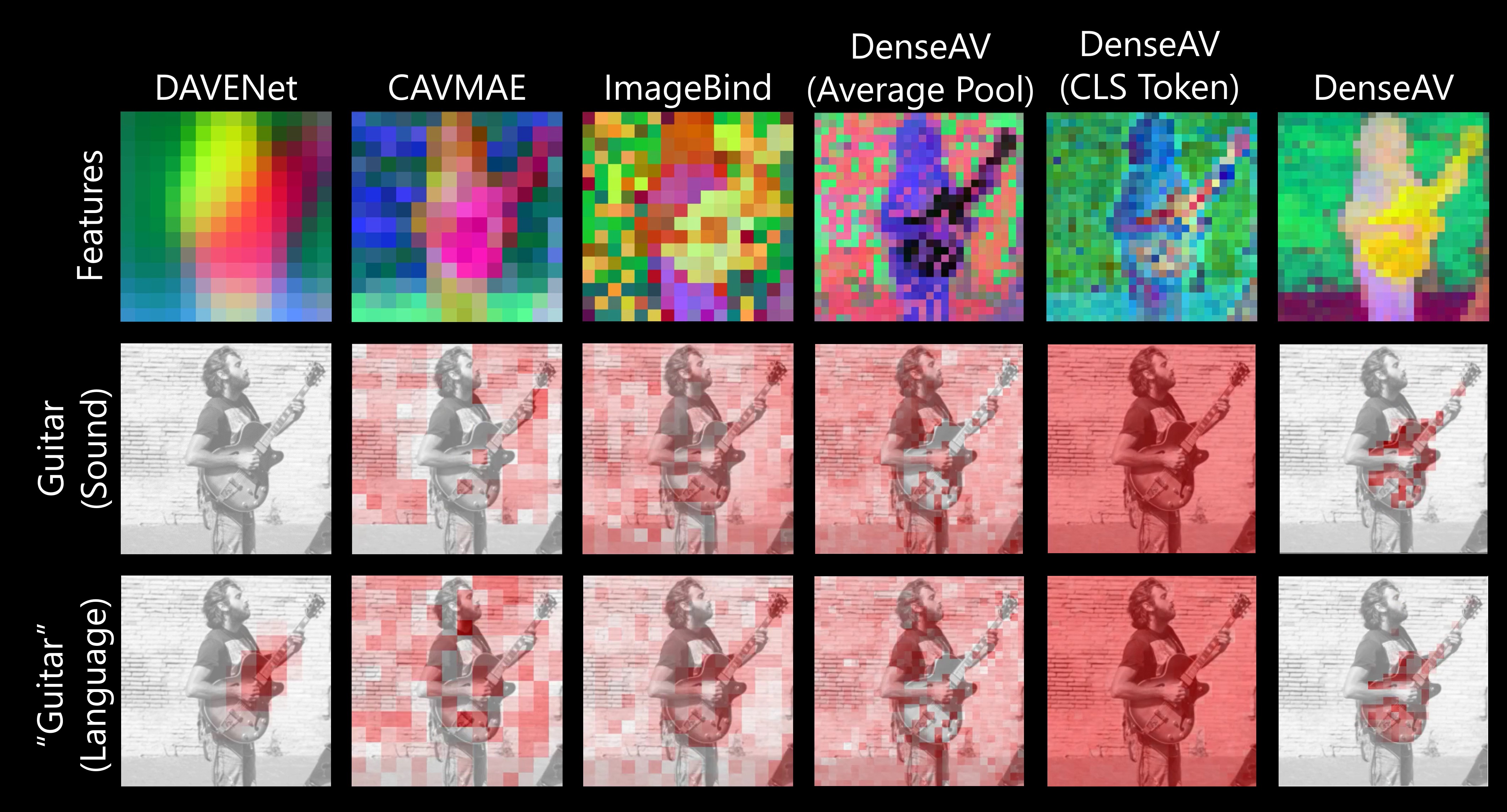
یکی از تفاوتهای بزرگ بین DenseAV و الگوریتمهای قبلی این است که کارهای قبلی بر روی یک مفهوم واحد از شباهت بین صدا و تصاویر تمرکز میکردند. مثلاً یک کلیپ صوتی کامل مانند کسی که میگوید “سگ روی چمن نشسته” با یک تصویر کامل از یک سگ تطابق داده میشد. این روش به الگوریتمهای قبلی اجازه نمیداد جزئیات دقیقی مانند ارتباط بین کلمه “چمن” و چمن زیر سگ را کشف کنند. اما الگوریتم تیم DenseAV به دنبال تطابقهای ممکن بین یک کلیپ صوتی و پیکسلهای یک تصویر میگردد و همه آنها را جمعآوری میکند. این کار نه تنها عملکرد مدل را بهبود بخشید، بلکه به تیم اجازه داد که صداها را دقیقاً مکانیابی کنند، چیزی که الگوریتمهای قبلی قادر به انجام آن نبودند. همیلتون میگوید: «روشهای متداول از یک توکن کلاسی واحد استفاده میکنند، اما روش ما هر پیکسل و هر ثانیه از صدا را با هم مقایسه میکند. این روش دقیق به DenseAV اجازه میدهد که ارتباطات جزئیتر و محلیسازی بهتری انجام دهد.»
پژوهشگران DenseAV را بر روی مجموعه داده AudioSet، که شامل ۲ میلیون ویدیو از یوتیوب است، آموزش دادند. آنها همچنین مجموعه دادههای جدیدی ایجاد کردند تا ببینند مدل چقدر میتواند صداها و تصاویر را به هم پیوند دهد. در این آزمایشها، DenseAV در کارهایی مانند شناسایی اشیا از روی نامها و صداهایشان عملکرد بهتری نسبت به دیگر مدلهای برتر داشت و کارایی خود را ثابت کرد. همیلتون میگوید: «مجموعه دادههای قبلی تنها از ارزیابیهای کلی پشتیبانی میکردند، بنابراین ما مجموعه دادهای ایجاد کردیم که از مجموعه دادههای تقسیمبندی معنایی استفاده میکند. این مجموعه داده کمک میکند تا مدل ما با استفاده از حاشیهنویسیهای دقیق پیکسلی ارزیابی دقیقی از عملکرد خود داشته باشد. ما میتوانیم الگوریتم را با صداها یا تصاویر خاص تحریک کنیم و مکانیابیهای دقیق دریافت کنیم.»
چالشها و پیشرفتها
به دلیل حجم عظیم دادههای مورد نیاز، این پروژه حدود یک سال به طول انجامید. تیم میگوید که گذار به یک معماری ترانسفورمر بزرگ چالشبرانگیز بود، زیرا این مدلها به راحتی میتوانند جزئیات دقیق را نادیده بگیرند. تمرکز دادن مدل بر روی این جزئیات یک مانع بزرگ بود.
در آینده، تیم قصد دارد سیستمهایی ایجاد کند که بتوانند از حجم عظیمی از دادههای فقط ویدیو یا فقط صوت یاد بگیرند. این کار برای حوزههای جدیدی که دادههای زیادی از یک نوع وجود دارد، اما نه هر دو با هم، حیاتی است. آنها همچنین قصد دارند از معماریهای بزرگتری استفاده کنند و شاید از دانش مدلهای زبانی نیز برای بهبود عملکرد استفاده کنند.
دیوید هارواث، استادیار علوم کامپیوتر در دانشگاه تگزاس در آستین، که در این کار دخیل نبود، میگوید: «تشخیص و تفکیک اشیا بصری در تصاویر و همچنین صداهای محیطی و کلمات گفتاری در ضبطهای صوتی هر کدام مشکلات خاص خود را دارند. به طور سنتی، محققان برای آموزش مدلهای یادگیری ماشین جهت انجام این کارها به برچسبگذاریهای گرانقیمت و انسانی وابسته بودند. DenseAV پیشرفت قابل توجهی در توسعه روشهایی برای یادگیری همزمان این وظایف تنها با مشاهده دنیا از طریق بینایی و شنوایی داشته است — با این بینش که چیزهایی که میبینیم و با آنها تعامل داریم معمولاً صدا تولید میکنند و ما نیز از زبان گفتاری برای صحبت درباره آنها استفاده میکنیم. این مدل همچنین هیچ فرضی درباره زبان خاصی که صحبت میشود ندارد و بنابراین به طور نظری میتواند از دادههای هر زبانی یاد بگیرد. هیجانانگیز خواهد بود که ببینیم DenseAV با مقیاسپذیری به هزاران یا میلیونها ساعت داده ویدئویی در انواع زبانها چه چیزهایی میتواند یاد بگیرد.»
تو سایت خود همیلتون (اینجا) میتونین از این الگوریتم و ویدئوهایی که ازشون برای آموزش استفاده شده، بازدید کنین!
این پست برگرفته از New algorithm discovers language just by watching videos | MIT News | Massachusetts Institute of Technology میباشد!


بدون دیدگاه