
الگوریتم Dense AV
DenseAV، الگوریتمی که در دانشگاه MIT توسعه داده شده، یاد میگیرد چگونه زبان را تحلیل کند و معنی آن را بفهمد، تنها با تماشای ویدیوهایی که افراد در آن صحبت میکنند. این الگوریتم قابلیتهای بالقوهای در جستجوی چندرسانهای، یادگیری زبان، و رباتیک دارد. مارک همیلتون، دانشجوی دکترای مهندسی برق و علوم کامپیوتر در MIT و یکی از اعضای آزمایشگاه علوم کامپیوتر و هوش مصنوعی MIT (CSAIL)، قصد دارد از ماشینها برای درک نحوه ارتباط حیوانات استفاده کند. برای رسیدن به این هدف، او ابتدا تصمیم گرفت سیستمی بسازد که بتواند زبان انسان را “از پایه” یاد بگیرد.
Dense AV از زبان همیلتون
همیلتون توضیح میدهد که ایده مدل از مشاهده واکنش احساسی یک پنگوئن در فیلم “مارش پنگوئنها” الهام گرفته شد؛ جایی که صدا جایگزینی برای زبان انسانی بود. این الهام باعث شد به این فکر برسند که شاید بتوان زبان را از طریق صدا و تصویر یاد گرفت. به همین دلیل، آنها مدل Dense AV را طراحی کردند که با تطبیق صدای شنیدهشده با تصویر دیدهشده و بالعکس، زبان را میآموزد. برای مثال، اگر جملهای درباره پخت کیک شنیده شود، مدل باید تصویری از کیک یا فر را پیشبینی کند و این تطبیق را با میلیونها ویدیو تمرین میکند.
پس از آموزش Dense AV در این بازی تطبیق، همیلتون و همکارانش به این موضوع پرداختند که مدل وقتی صدایی را میشنود، به کدام پیکسلها نگاه میکند. برای مثال، وقتی کسی میگوید «سگ»، الگوریتم بلافاصله شروع به جستجو برای سگ در جریان ویدیو میکند. با دیدن پیکسلهایی که توسط الگوریتم انتخاب میشوند، میتوان فهمید که الگوریتم فکر میکند یک کلمه به چه معنی است.
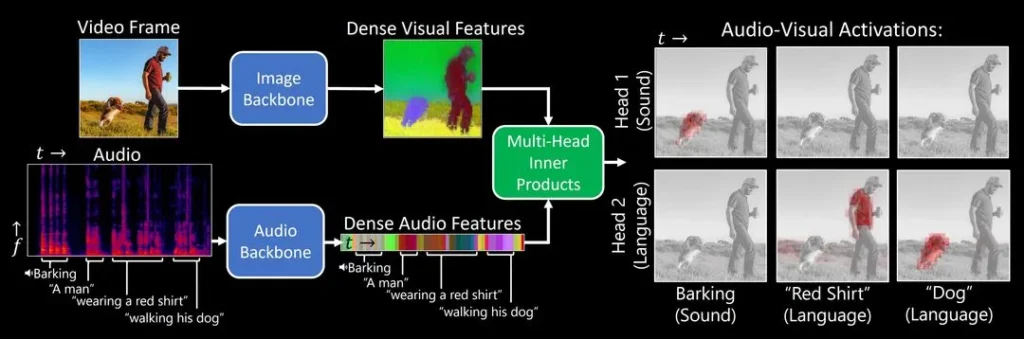
چگونگی عملکرد Dense AV
مدل Dense AV با هدف یادگیری زبان از طریق تطبیق صدا و تصویر طراحی شده، بدون اتکا به متن یا برچسبگذاری انسانی. برای مثال، وقتی صدای پارس سگ را میشنود، بهدنبال تصویر سگ در ویدیو میگردد. تیم با افزودن یک “مغز دوطرفه” دریافت که یک بخش مدل روی زبان (مثلاً کلمه “سگ”) و بخش دیگر روی صدا (پارس سگ) تمرکز میکند. این یعنی Dense AV توانسته مفاهیم چندحسی را بهدرستی تفکیک کند.
این مدل با یادگیری تضادآمیز، یعنی مقایسه جفتهای صوتی-تصویری و تشخیص شباهت یا تفاوت آنها، بدون نیاز به داده برچسبخورده آموزش میبیند. هدف نهایی، درک زبانهای نوشتارندار مانند زبان دلفینها یا حتی تحلیل صداهای لرزهای زمین است. این مسیر مشابه یادگیری زبان توسط کودکان است؛ تنها از راه شنیدن و دیدن.
برتری Dense AV نسبت به سایر الگوریتم های تشخیص
برخلاف مدلهای قبلی که فقط تطابق کلی بین یک جمله و یک تصویر کامل را بررسی میکردند، Dense AV بهصورت جزئیتر کار میکند و صدا را با هر پیکسل تصویر تطبیق میدهد. این روش باعث شده تا مدل بتواند روابط دقیقتری مثل کلمه “چمن” و مکان چمن در تصویر را کشف کند و صداها را بهصورت مکانی شناسایی کند.
Dense AV با استفاده از دیتاست عظیم AudioSet (شامل ۲ میلیون ویدیو از یوتیوب) و مجموعه دادههای جدیدی که پژوهشگران طراحی کردند، آموزش دید. این مدل در تطبیق نام اشیا با تصویر یا صدایشان بهتر از الگوریتمهای قبلی عمل کرد. برای ارزیابی دقیقتر، تیم از دادههایی با حاشیهنویسی پیکسلی استفاده کرد تا عملکرد مدل در مکانیابی اشیا بر اساس صدا یا نام، بهصورت دقیق سنجیده شود.
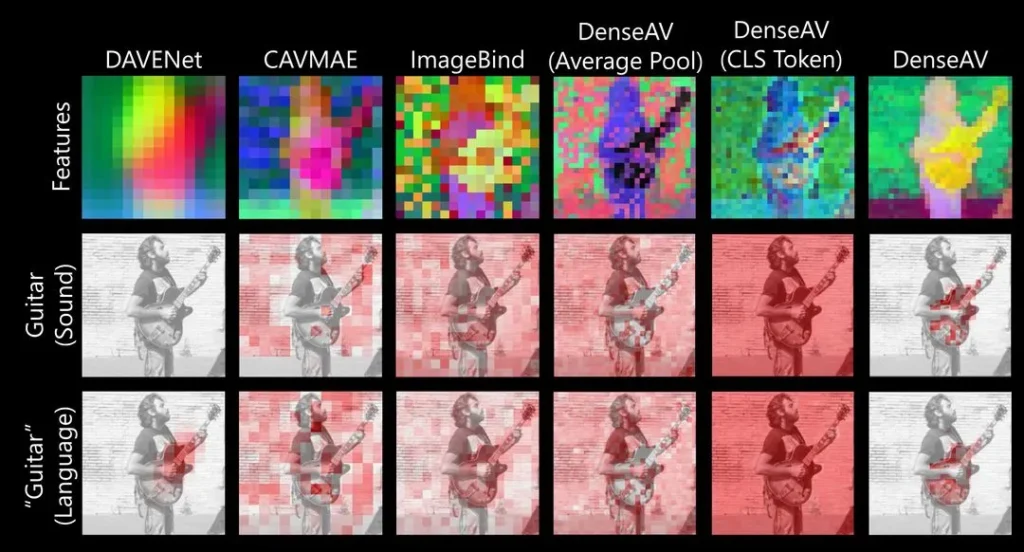
چالشها و پیشرفتها
پروژه Dense AV بهدلیل نیاز به دادههای حجیم و گذار دشوار به معماری ترانسفورمر حدود یک سال زمان برد. یکی از چالشهای اصلی، واداشتن مدل به توجه به جزئیات ظریف بود، چون معماریهای بزرگ معمولاً آنها را نادیده میگیرند.
تیم در آینده میخواهد سیستمهایی بسازد که فقط با دادههای صوتی یا فقط تصویری یاد بگیرند، که برای حوزههایی با داده تکسویه بسیار کاربردی است. همچنین قصد دارند از مدلهای بزرگتر و شاید دانش زبان طبیعی برای بهبود عملکرد استفاده کنند.
به گفته دیوید هارواث، Dense AV بدون نیاز به برچسبگذاری انسانی، میتواند همزمان صداها، تصاویر و زبان گفتاری را یاد بگیرد. این مدل زبانمحور نیست و پتانسیل یادگیری از هر زبان و میلیونها ساعت ویدیوی چندزبانه را دارد، که میتواند درک مدل از ارتباطات انسانی را بهطرز چشمگیری گسترش دهد.
در وبسایت همیلتون (اینجا) میتوانید از این الگوریتم و ویدئوهایی که از آن ها برای آموزش استفاده شده است، بازدید کنید!
این پست برگرفته از New algorithm discovers language just by watching videos | MIT News | Massachusetts Institute of Technology میباشد!

{kind=link}
بدون دیدگاه