مروری جامع بر روشهای فاین تیونینگ در مدلهای زبانی بزرگ
در سالهای اخیر، مدلهای زبانی بزرگ (Large Language Models – LLMs) مانند GPT، BERT و T5 تحولی اساسی در حوزهی پردازش زبان طبیعی ایجاد کردهاند. این مدلها با آموزش اولیه بر حجم عظیمی از متون، الگوهای عمومی زبان، ساختار جمله و معناشناسی را میآموزند. با این حال، آموزش اولیه بهتنهایی برای دستیابی به عملکرد مطلوب در وظایف خاص یا حوزههای تخصصی کافی نیست.برای پر کردن این شکاف، فرایندی به نام تنظیم دقیق (Fine-Tuning) مورد استفاده قرار میگیرد. در این مرحله، مدل ازپیشآموزشدیده با مجموعهدادهای کوچکتر و تخصصیتر دوباره آموزش داده میشود تا بتواند بهطور دقیقتری با نیازهای خاص یک وظیفه یا دامنه سازگار شود.
برخلاف آموزش اولیه که بر یادگیری دانش کلی زبان تمرکز دارد، تنظیم دقیق باعث تخصصی شدن مدل میشود. به این ترتیب، یک معماری ثابت میتواند برای حوزههای گوناگون مانند پزشکی، حقوق، یا ترجمهی ماشینی به کار رود، بدون نیاز به آموزش مجدد از صفر.
در سالهای اخیر، روشهای کارآمدتری مانند تنظیم دقیق پارامتر-بهینه (PEFT) شامل LoRA، Prefix-Tuning و Adapter-Tuning معرفی شدهاند که امکان تنظیم مدلهای بزرگ را با منابع سختافزاری محدود فراهم میکنند. افزون بر این، تنظیم دقیق در بهبود توانایی مدل در پیروی از دستورها (Instruction Following) و تولید پاسخهای سازگار و دقیق نقش مهمی دارد.
مبانی نظری Fine-Tuning
مدلهای زبانی بزرگ عمدتاً بر پایهی معماری ترنسفورمر (Transformer) ساخته میشوند که نخستینبار توسط Vaswani و همکارانش در سال ۲۰۱۷ معرفی شد. این معماری بر سازوکار توجه به خود (Self-Attention) تکیه دارد تا وابستگیهای بلندمدت در متن را درک کند و معنا را در سطح جمله و پاراگراف استخراج نماید.
در مرحلهی آموزش اولیه (Pre-training)، مدلها در معرض میلیاردها کلمه از منابع متنوع مانند کتابها و صفحات وب قرار میگیرند تا الگوهای زبانی عمومی را بیاموزند. با این حال، دانش بهدستآمده در این مرحله عمومی است و برای وظایف خاص (مثلاً تحلیل احساسات یا پاسخ به پرسشها) کافی نیست.
اینجاست که فاین تیونینگ (Fine-Tuning) وارد عمل میشود. این فرایند نوعی یادگیری انتقالی (Transfer Learning) است که در آن دانش عمومی مدل برای یک دامنهی خاص تطبیق داده میشود. در نتیجه، با صرف داده و منابع کمتر، مدل به کارایی بالاتری در وظایف تخصصی دست مییابد.
برای درک بهتر قدرت چتباتها، همین حالا مقالهی «مفهوم RAG چیست و چه کاربردی در چتبات دارد؟» را از دست ندهید!
بنابراین، مبانی نظری تنظیم دقیق در تلاقی سه مفهوم قرار دارد:
معماری ترنسفورمر،
یادگیری انتقالی،
و سازگاری با دامنهی خاص (Domain Adaptation).
روشهای فاین تیونینگ
فرایند تنظیم دقیق از روشهای گوناگونی تشکیل شده که بسته به منابع، اندازهی مدل و نوع داده، میتوان از آنها استفاده کرد.
1.فاین تیونینگ کامل (Full Fine-Tuning)
در این روش، تمام پارامترهای مدل بهروزرسانی میشوند. اگرچه این روش دقیقترین سازگاری را ایجاد میکند، اما هزینهی محاسباتی بسیار بالایی دارد و ممکن است باعث فراموشی فاجعهآمیز (Catastrophic Forgetting) شود، یعنی مدل دانش عمومی قبلی خود را از دست بدهد.
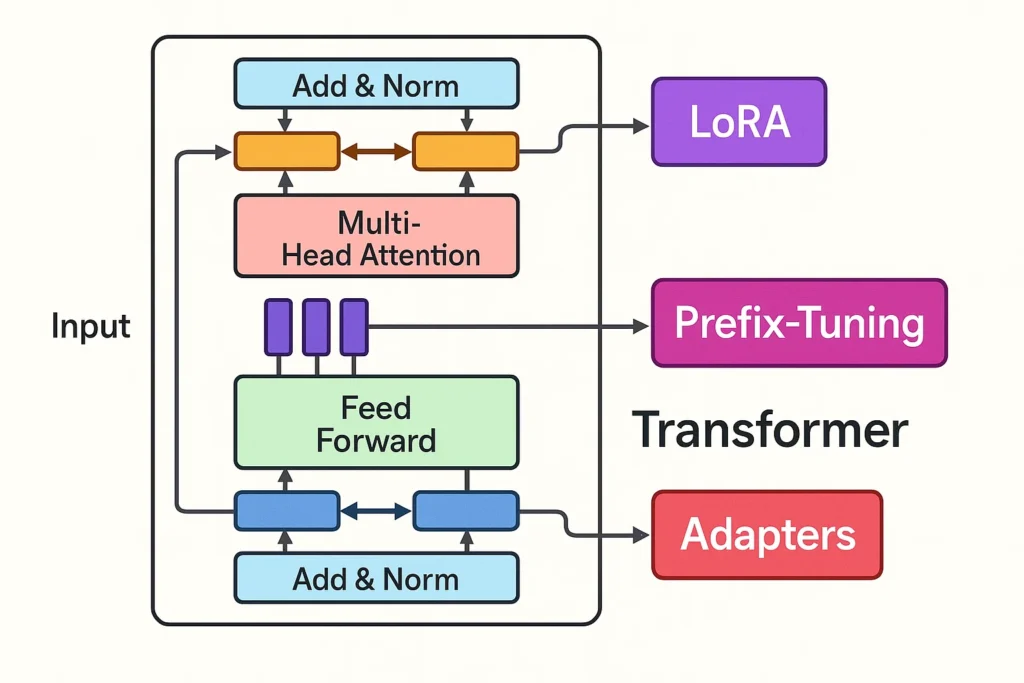
2.فاین تیونینگ کارآمد (Parameter-Efficient Fine-Tuning - PEFT)
برای کاهش هزینهها، روشهای کارآمدتری طراحی شدهاند که تنها بخش کوچکی از پارامترها را بهروزرسانی میکنند یا ماژولهای جدیدی به مدل اضافه میکنند.
- LoRA (Low-Rank Adaptation): افزودن ماتریسهای کمرتبهی قابل یادگیری به لایههای مدل.
Prefix-Tuning: افزودن بردارهای قابل یادگیری در ابتدای ورودی هر لایه.
Adapter-Tuning: قرار دادن ماژولهای کوچک بین لایهها که فقط آنها آموزش میبینند.
BitFit: تنظیم تنها بایاسها با کمترین هزینه محاسباتی.
3.فاین تیونینگ بر اساس دستور (Instruction Fine-Tuning)
در این روش، مدل با دادههایی شامل پرسشها و پاسخهای انسانی تنظیم میشود تا توانایی پیروی از دستورها و تولید پاسخهای طبیعیتر را پیدا کند (همانند مدلهای InstructGPT).
4.فاین تیونینگ دامنهای (Domain-Specific Fine-Tuning)
در این نوع، دادههای آموزشی از یک حوزهی خاص (مثلاً پزشکی یا حقوقی) انتخاب میشوند تا مدل واژگان و مفاهیم تخصصی همان حوزه را بیاموزد.
ارزیابی عملکرد مدلهای تنظیمشده Fine-Tuning
ارزیابی عملکرد مدلهای تنظیمشده یکی از مهمترین مراحل در فرایند توسعهی مدلهای زبانی است. هدف از ارزیابی، سنجش میزان سازگاری، دقت و توانایی تعمیم مدل به دادههای جدید است.
_ معیارهای کمی
معیارهای متداول شامل دقت (Accuracy)، امتیاز BLEU برای ترجمه، F1-Score برای دستهبندی، و Perplexity برای پیشبینی توکنها هستند. این معیارها عملکرد عددی مدل را در وظایف مختلف نشان میدهند، اما بهتنهایی برای سنجش کیفیت واقعی کافی نیستند.

_ معیارهای کیفی
در مدلهای زبانی بزرگ، ارزیابی کیفی نیز اهمیت ویژهای دارد. معیارهایی مانند سازگاری معنایی، دقت واقعی (Factual Accuracy)، روانسازی زبانی (Fluency) و همخوانی با ارزشهای انسانی (Alignment) نقش کلیدی دارند. این ارزیابی معمولاً با قضاوت انسانی یا مدلهای ارزیاب (Evaluator Models) انجام میشود.
_ بنچمارکها و آزمونهای استاندارد
پژوهشگران برای مقایسهی مدلها از بنچمارکهای استانداردی مانند GLUE، SuperGLUE، MMLU و MT-Bench استفاده میکنند. این آزمونها عملکرد مدل را در مجموعهای از وظایف زبانی، استدلالی و دانشی ارزیابی میکنند.
در مجموع، ارزیابی مدلهای تنظیمشده باید چندبُعدی باشد تا هم جنبههای فنی و هم جنبههای اخلاقی و معنایی در نظر گرفته شوند.
کاربردهای فاین تیونینگ (Applications)
تنظیم دقیق مدلهای زبانی بزرگ در سالهای اخیر کاربردهای گستردهای در علوم مختلف پیدا کرده است.
برای درک بهتر رقابت میان دو روش قدرتمند، حتماً مقالهی «تفاوتهای RAG و Fine-Tuning: نبرد دو روش برای آموزش مدلهای زبانی بزرگ» را مطالعه کنید!
1. ترجمه ماشینی
مدلهایی که با دادههای چندزبانه تنظیم دقیق میشوند، توانایی ترجمهی دقیقتر و روانتری را به دست میآورند. پژوهشهای اخیر نشان دادهاند که با استفاده از Fine-Tuning، میتوان عملکرد مدل را برای زبانهای کممنبع نیز بهبود داد.
چگونه از فاینتیونینگ در ترجمه ماشین استفاده میشود؟
یک مدل چندزبانه یا عمومی مانند mBART ،mT5 یا LLaMA با مجموعهدادههای ترجمهی یک زبان خاص دوباره آموزش داده میشود تا:
واژگان آن زبان را بهتر یاد بگیرد
ساختارهای دستوری زبان را دقیقتر ترجمه کند
در متون تخصصی (پزشکی، حقوقی، فنی) خطا کمتر شود
مثال:
Fine-Tuning mT5 با دادههای فارسی–انگلیسی برای ساخت یک مترجم بهتر از گوگل در حوزهی خبر.
تنظیم دقیق یک مدل روی جفتزبان عربی–فارسی برای ترجمهی متون مذهبی.
فاینتیون LLaMA با دادههای موازی پزشکی → مترجم تخصصی برای گزارشهای بیمارستانی.
2. تحلیل احساسات و بازخوردها
در حوزهی کسبوکار و شبکههای اجتماعی، تنظیم دقیق مدلها بر دادههای مشتریان باعث میشود تا مدل بتواند احساسات مثبت یا منفی را بهطور دقیقتر شناسایی کند.
چگونه از فاینتیونینگ در تحلیل احساسات و بازخوردها استفاده میشود؟
مدل پایه (مثلاً BERT یا RoBERTa) را روی مجموعهدادهای شامل نظرات کاربران، کامنتها یا پستهای شبکههای اجتماعی دوباره آموزش میدهند.
در این فاینتیونینگ، مدل یاد میگیرد که متن مثبت، منفی یا خنثی است.
مثال:
فاینتیون BERT روی کامنتهای دیجیکالا برای تشخیص رضایت مشتری.
تنظیم دقیق یک مدل روی توییتهای فارسی جهت تحلیل احساسات دربارهی یک برند.
ساخت سیستم تحلیل متن برای پیشبینی واکنش مردم به یک کمپین تبلیغاتی.
3.پزشکی (Clinical NLP / Biomedical NLP)
در حوزهٔ پزشکی، فاینتیونینگ باعث میشود مدل با آموزش روی دادههای تخصصی مانند مقالات علمی، گزارشهای بیمار و اصطلاحات بالینی، توانایی درک و تولید دقیق متون پزشکی را پیدا کند.
چگونه از فاینتیونینگ درپزشکی استفاده میشود؟
مدل با دادههای تخصصی پزشکی (مقالات PubMed، گزارشهای بیمار، ویزیتنامهها) تنظیم دقیق میشود.
در این حالت مدل زبان حرفهای و اصطلاحات دقیق را یاد میگیرد.
مثال:
Fine-Tuning BioBERT روی گزارشهای CT اسکن برای استخراج تشخیص.
تنظیم دقیق GPT برای خلاصهسازی پروندهی پزشکی بیمار.
فاینتیون T5 برای تشخیص خودکار داروها، بیماریها و علائم در متن.
5. پیروی از دستور (Instruction Following)
مدل با آموزش روی هزاران جفت دستور–پاسخ، طوری تنظیم میشود که مثل یک چتبات پاسخهای شفاف، کوتاه و درست ارائه دهد.
چگونه از فاینتیونینگ درسوال جواب استفاده میشود؟
مدل با هزاران جفت دستور → پاسخ تنظیم دقیق میشود تا مثل یک چتبات رفتار کند و پاسخهای شفاف، کوتاه و درست بدهد.مقاله ی مرتبط با این موضوع یعنی (چگونه مدلهای زبانی خودشان را بهتر میکنند؟)مطالعه داشته باشید.
مثال:
فاینتیون LLaMA روی دادههای Alpaca یا Dolly برای آموزش رفتار محاورهای.
ساخت نسخهی اختصاصی ChatGPT برای یک شرکت با دادههای دستور–پاسخ داخلی.
آموزش مدل برای اجرای دستورهایی مثل «شعر بساز»، «کد بنویس»، «خلاصه کن»
4.خلاصهسازی متن (Summarization)
در حوزهٔ خلاصهسازی متن، فاینتیونینگ مدل را قادر میسازد تا با یادگیری از نمونههای «متن طولانی → خلاصه»، بتواند محتوای گسترده را به شکلی دقیق، منسجم و کوتاه تبدیل کند.
چگونه از فاین تیونینگ در خلاصه سازی متن استفاده میشود؟
مدلهای Encoder–Decoder مثل T5 با دادهای شامل متن طولانی → خلاصه دوباره آموزش داده میشوند.
اگر میخواهید تصویر واضحتری از دنیای پردازش زبان طبیعی داشته باشید، مطالعهی مقالهی «مقدمهای بر NLP و نقش یادگیری عمیق در تحول درک زبان انسان» را از دست ندهید.
مثال:
فاینتیون T5 برای خلاصهسازی اخبار روزانه.
آموزش مدل برای خلاصهسازی صورتجلسه جلسات شرکتها.
خلاصهسازی مقالات دانشگاهی برای پژوهشگران.
چالشها و محدودیتهای Fine-Tuning
با وجود مزایای چشمگیر، فرایند تنظیم دقیق با چالشهای متعددی همراه است:
کمبود دادههای باکیفیت
در بسیاری از حوزههای تخصصی، دادههای کافی و معتبر در دسترس نیست. دادههای محدود یا مغرضانه میتوانند موجب تولید خروجیهای نادرست یا جهتدار شوند.
فراموشی دانش قبلی
در طی تنظیم دقیق، مدل ممکن است دانش عمومی خود را از دست بدهد. این پدیده که «فراموشی فاجعهآمیز» نام دارد، یکی از مشکلات بنیادی در یادگیری انتقالی است.
هزینهی محاسباتی
تنظیم دقیق مدلهای بزرگ مستلزم سختافزار قدرتمند و مصرف بالای انرژی است، که مانعی برای پژوهشگران مستقل یا مؤسسات کوچک به شمار میرود.
نتیجهگیری و جمعبندی
مدلهای زبانی بزرگ در سالهای اخیر بهعنوان هستهی اصلی بسیاری از سامانههای هوشمند مطرح شدهاند، اما آنها بدون فاین تیونینگ(Fine-Tuning) توان پاسخگویی مناسب به نیازهای تخصصی را ندارند.فاین تیونینگ این امکان را میدهد که یک مدل ازپیشآموزشدیده با صرف دادهی کمتر، برای وظایف خاص، دامنههای تخصصی و نیازهای کاربران تطبیق پیدا کند.
اگر میخواهید بدانید چگونه یک مدل زبانی بزرگ از صفر و با یادگیری خودتکاملی ساخته میشود، مقالهی «R-Zero» را از دست ندهید.
پیشرفت روشهایی مانند PEFT، LoRA، Prefix-Tuning و Adapter-Tuning سبب شده که فرایند تنظیم مدلهای بزرگ، کمهزینهتر و در دسترستر شود؛ بهگونهای که حتی با منابع سختافزاری محدود نیز امکان آموزش نسخههای تخصصی مدل فراهم باشد.
علاوه بر این، فاین تیونینگ نقش مهمی در Alignment، توانایی پیروی از دستور (Instruction Following) و تخصصیسازی معنایی دارد. ارزیابی این مدلها نیز باید چندبُعدی باشد؛ زیرا تنها معیارهای عددی مانند Accuracy یا BLEU نمیتوانند کیفیت واقعی، سازگاری معنایی و دقت factual را نشان دهند.
پیشرفت روشهای کارآمد (PEFT) و افزایش کیفیت دادهها باعث شده تطبیق مدلها آسانتر و دقیقتر شود. در کنار این، ارزیابی چندبُعدی (کمی + کیفی) تضمین میکند که مدلهای تنظیمشده نهتنها دقیق، بلکه قابلاعتماد و اخلاقمدار باشند.

{kind=link}
بدون دیدگاه