چطور RAG دنیای مدلهای زبانی را متحول کرد؟ از مفهوم تا کاربردهای واقعی
مقدمه
رشد مدلهای زبانی بزرگ (LLMs) مانند GPT، T۵ و LLaMA باعث شد توانایی تولید زبان طبیعی به سطحی چشمگیر برسد. با این حال، این مدلها دانش خود را از دادههای آموزشی استخراج میکنند و پس از اتمام آموزش قادر به بهروزرسانی اطلاعات نیستند. مقاله “ترکیب RAG Fine-TUNING :نبرد دو روش برای آموزش مدل های زبانی بزرگ” را حتما مطالعه کنید.
مشکل دیگر، توهم اطلاعات (hallucination) است — زمانی که مدل با اطمینان اطلاعاتی نادرست یا ساختگی تولید میکند.
در سال ۲۰۲۰، Lewis و همکاران مدل Retrieval-Augmented Generation (RAG) را معرفی کردند تا این محدودیتها رفع شود. مدل، دو رویکرد متفاوت را ترکیب میکند: حافظه پارامتریک مدل (دانش ذخیرهشده در وزنها) و حافظه غیرپارامتریک (دانش بیرونی که از پایگاههای اطلاعاتی بازیابی میشود).
RAG پاسخهایی مستند و بهروز تولید میکند که هم خلاقیت زبانی مدل را نشان میدهد و هم دقت مبتنی بر دادههای واقعی دارد.
فهرست مطالب
مروری بر معماری مدلهای زبانی و محدودیتهای آنها
محققان مدلهای زبانی بزرگ (LLMs) را با میلیونها پارامتر و دادههای متنی عظیم آموزش میدهند.با وجود قدرت زیادشان، دو محدودیت اساسی دارند:
عدم دسترسی به اطلاعات جدید — پس از آموزش، مدل نمیتواند دادههای جدید یاد بگیرد مگر اینکه دوباره آموزش داده شود.
فقدان شفافیت در منشأ دانش — پژوهشگران نمیتوانند مشخص کنند اطلاعات تولیدشده از کدام منبع آمده است.
مقالات Survey (۲۰۲۴, ۲۴۱۰) نشان میدهند که این دو چالش باعث شدند RAG تولد یابد؛ این مدل هنگام پاسخدهی اطلاعات تازه را از حافظه بیرونی فراخوانی میکند. این ایده، نوعی اتصال میان سیستمهای جستجو (Information Retrieval) و مدلهای زبانی است.
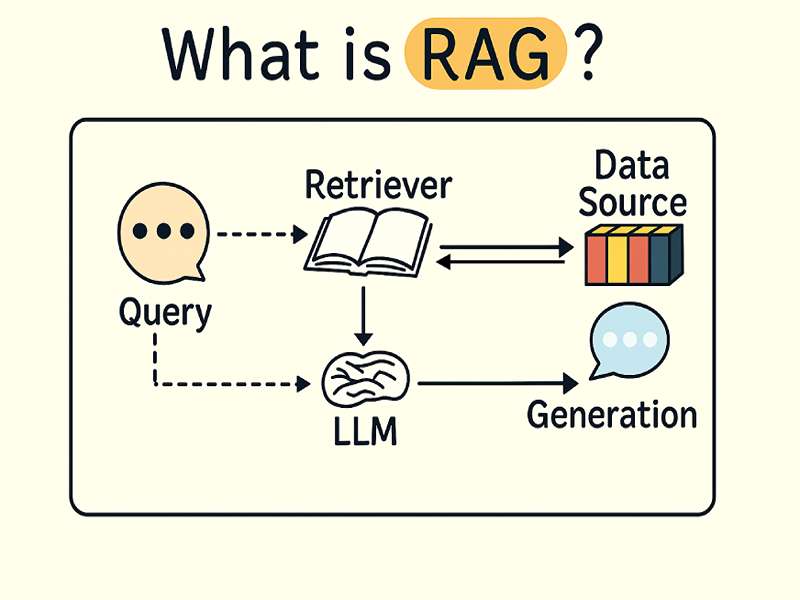
مفهوم RAG چیست؟
بهطور خلاصه، RAG = Retrieval + Generation.
مدل ابتدا با یک retriever اسناد مرتبط را از یک پایگاه داده برداری پیدا میکند، سپس با استفاده از یک generator پاسخ نهایی را بر اساس این اسناد میسازد.
مقالهٔ Lewis et al. (۲۰۲۰) دو گونه اصلی را معرفی میکند: RAG-Sequence و RAG-Token.
RAG-Sequence: تمام توالی خروجی بر اساس یک سند تولید میشود.
RAG-Token: هر توکن خروجی میتواند بر اساس سند متفاوتی شرطی شود.
مروریهای ۲۰۲۴ نشان میدهند که پژوهشگران این مفهوم را توسعه داده و با روشهایی مثل rerankerها، cross-encoder retrieval و context compression ترکیب کردند.
مقاله ی “مقدمهای بر NLP و نقش یادگیری عمیق در تحول درک زبان انسان” حتما مطالعه کنید.
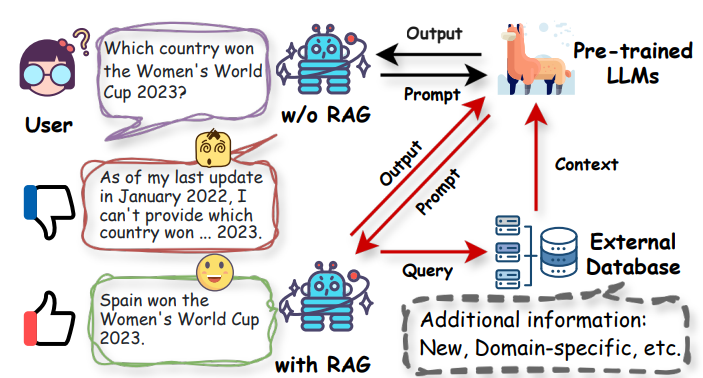
فرآیند کار RAG
فرآیند استاندارد RAG شامل چند گام اصلی است که پژوهشگران برای تولید پاسخهای دقیق و مستند از آن استفاده میکنند:
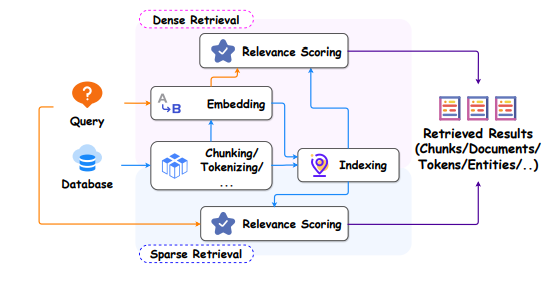
Encoding Query: مدلهای embedding مانند DPR پرسش یا ورودی کاربر را به بردار تبدیل میکنند تا برای بازیابی اسناد آماده شود.
Retrieval: سیستم جستجوی برداری در پایگاه دادهای مانند FAISS یا Pinecone انجام میدهد و نزدیکترین top-K اسناد مرتبط را بازیابی میکند.
Aggregation: سیستم اسناد بازیابیشده را انتخاب کرده و در صورت نیاز ترکیب میکند تا اطلاعات مفید برای تولید پاسخ آماده شود.
Generation: مدل تولیدگر (مثل BART یا T۵) پرسش و اسناد بازیابیشده را پردازش کرده و پاسخ نهایی را تولید میکند.
مقالهٔ اصلی RAG (Lewis et al., 2020) فرآیند را با فرمولهای ریاضی توضیح میدهد و نشان میدهد چگونه مدل خروجی را بهصورت احتمالاتی بر پایهٔ مجموعهای از اسناد محاسبه میکند.
این چهار مرحله، پایه و اساس ساختار RAG هستند و به مدل اجازه میدهند در مواجهه با پرسشهای جدید یا خارج از دادههای آموزشی، پاسخهایی دقیق و مستند تولید کند.
نمونهی پیادهسازی RAG
پژوهشگران معمولاً فرآیند RAG را به چهار گام عملی تقسیم میکنند تا مدلهای زبانی بتوانند پاسخهای دقیق و مستند تولید کنند:
1.ایجاد بردارهای متنی (Embedding):
مدلهای embedding هر سند یا پاراگراف در پایگاه دانش را به بردار تبدیل میکنند. این بردارها نمایش عددی متن را فراهم میکنند تا عملیات بازیابی آسانتر شود.
2.ایجاد پایگاه داده برداری (Vector Store):
سیستم بردارهای ایجادشده را در پایگاه دادهای مانند FAISS یا Pinecone ذخیره میکند تا در مراحل بعد بتوان به سرعت اسناد مرتبط را جستجو کرد.
3.بازیابی (Retrieval):
وقتی کاربر پرسشی مطرح میکند، سیستم بردار embedding متن پرسش را ایجاد کرده و نزدیکترین بردارها از پایگاه داده را بازیابی میکند. این کار تضمین میکند که مدل از اطلاعات مرتبط برای تولید پاسخ استفاده کند.
4.تولید پاسخ (Generation):
مدل زبانی (مثلاً GPT، T۵ یا LLaMA) پرسش و اسناد بازیابیشده را پردازش میکند و پاسخ نهایی را تولید میکند. این پاسخ هم دقیق و مستند است و هم قابلیت تولید زبان طبیعی را حفظ میکند.
نکات بهینهسازی
مطابق مقاله Finetune-RAG (2025):
- میتوان generator را با دادههای دارای نویز آموزشی داد تا در برابر contextهای نادرست مقاوم شود.
استفاده از cross-encoder reranker پس از بازیابی باعث بهبود دقت factual میشود.
برای دادههای سازمانی، chunking تطبیقی و metadata filtering کیفیت نتایج را بالا میبرند.
فناوریها و ابزارهای کلیدی
Retriever: پیادهسازان اولیه از DPR (Dense Passage Retriever) بهعنوان Retriever استفاده کردند.
Generator: معمولاً مدلهای seq2seq مثل BART، T5 یا FLAN-T5.
Vector Database: ابزارهایی نظیر FAISS، Pinecone، Weaviate، Milvus برای نگهداری embeddingها.
Frameworkها: LangChain و LlamaIndex امروزه چارچوبهایی برای ساخت pipelineهای RAG فراهم کردهاند (در Survey 2024 ذکر شده است).

کاربردهای RAG
مقالهٔ ۲۰۲۰ و مروریهای بعدی نشان میدهند که RAG در حوزههای زیر کاربرد دارد:
- پرسشوپاسخ باز (Open-domain QA): مثلاً روی دیتاستهای NaturalQuestions و WebQuestions.
چتباتهای سازمانی: برای استفاده از دادههای داخلی شرکتها.
تحلیل متون تخصصی: پزشکی، مالی، حقوقی.
Fact Verification: ارزیابی صحت ادعاهای خبری یا علمی.
در مقالهٔ Survey (2024)، از RAG بهعنوان «هستهٔ نسل جدید موتورهای پاسخگو» یاد شده است.
مزایا و چالشها
بهروزرسانی سریع دانش: بدون نیاز به بازآموزی مدل.
کاهش hallucination: چون مدل مستندات واقعی را در اختیار دارد.
قابلیت تبیین: منشأ پاسخ قابل ردیابی است.
چالشها
بازیابی اشتباه: اگر retriever سند اشتباه برگرداند، مدل خروجی گمراهکننده تولید میکند.
توهم (Hallucination): حتی با اسناد درست، generator ممکن است تفسیر نادرست تولید کند.
هزینه محاسباتی: اجرای retrieval و generation بهصورت زنجیرهای کند است.
مقالهٔ Finetune-RAG (۲۰۲۵) روشهایی ارائه میدهد تا hallucination کاهش یابد. آموزش مجدد generator بر اساس مثالهایی که حاوی context اشتباه هستند تا مدل در مواجهه با دادههای نادرست مقاوم شود.ن
مقایسه RAG با سایر روشها
| ویژگی | Fine-tuning سنتی | RAG | Retrieval-only |
|---|---|---|---|
| بهروزرسانی دانش | نیازمند آموزش دوباره | سریع (با تعویض پایگاه) | سریع |
| نیاز به حافظه زیاد | زیاد | متوسط | کم |
| کنترل منشأ داده | محدود | شفاف | شفاف |
| توان زبانی | بالا | بالا | محدود |
نتیجهگیری و آیندهی RAG
تمام مقالات مروری تاکید میکنند که RAG تنها یک مرحله میانی از تحول LLM هاست.
آیندهٔ پژوهشها شامل:
Retrieval-generation مشترک (joint training)،
خودارزیابی factuality با مدلهای ارزیاب،
ترکیب RAG با عاملهای هوشمند (AI Agents)،
RAG چندمدیالی (متن+تصویر+کد)،
کارایی بالاتر در مقیاس بزرگ (streaming retrieval) است.
RAG اکنون به عنوان پایهای برای مدلهای نسل بعدی LLMها (مانند ChatGPT-RAG و LlamaIndex-integrated systems) شناخته میشود و به نظر میرسد مسیر اصلی توسعهٔ مدلهای زبانی در آینده خواهد بود.

{kind=link}
مچکرم از مقاله ی خوبتون