
SAPO راهی تازه برای آموزش مدلهای زبانی با یادگیری تقویتی جمعی
در چند سال گذشته، مدلهای زبانی (Language Models یا LMs) از ابزارهایی ساده برای تکمیل جمله، به سیستمهایی با توانایی درک و استدلال پیچیده تبدیل شدهاند. با این حال، بیشتر پیشرفتها از طریق پیشتمرین (Pre-training) و یادگیری با نظارت (Supervised Fine-tuning) حاصل شده است — یعنی مدلها با مشاهدهی حجم عظیمی از دادههای انسانی آموزش دیدهاند تا ساختار زبان و الگوهای فکری ما را تقلید کنند.
اما مرحلهی بعدی تکامل مدلها دیگر فقط تکرار دادههای گذشته نیست، بلکه یادگیری از تجربه است. درست مثل انسانها، مدلها باید بتوانند از «اشتباهات» خود یاد بگیرند، تصمیم بگیرند، و با آزمون و خطا پیشرفت کنند. اینجا است که یادگیری تقویتی (Reinforcement Learning یا RL) وارد ماجرا میشود.
چرا یادگیری تقویتی برای مدلهای زبانی مهم است؟
روشهای سنتی مثل RLHF (Reinforcement Learning from Human Feedback) و نسخههای جدیدتر مثل RLVR (Reinforcement Learning with Verifiable Rewards) به مدلها اجازه میدهند تا از بازخورد — انسانی یا برنامهای — یاد بگیرند.
به عنوان مثال، وقتی مدلی پاسخ درستی به سؤال ریاضی یا منطقی میدهد، پاداش میگیرد، و اگر اشتباه کند، از آن تجربه برای بهبود عملکرد خود استفاده میکند.
میتوانید به مقاله الگوریتم خود نظارتی هم مراجعه کنید.
اما یک مشکل اساسی وجود دارد:
برای اینکه یادگیری تقویتی مؤثر باشد، باید در مقیاس بزرگ و بهصورت موازی انجام شود — یعنی هزاران نسخه از مدل باید همزمان تجربه جمع کنند و اطلاعات خود را به اشتراک بگذارند.
در عمل، این کار نیازمند زیرساختهای عظیم GPU، هماهنگی پیچیده بین سرورها، و هزینههای نجومی است.
ایدهی جدید: Swarm Sampling Policy Optimization (SAPO)
تیم Gensyn AI در مقالهی «Sharing is Caring» راهی تازه پیشنهاد میکند:
به جای اینکه همهی مدلها زیر نظر یک مرکز مشترک آموزش ببینند، هر کدام بهصورت مستقل ولی در ارتباط با دیگران یاد میگیرند.
آنها این روش را Swarm Sampling Policy Optimization یا به اختصار SAPO نامیدند.
ایده ساده اما قدرتمند است:
هر مدل (یا Node) مثل یک موجود مستقل در یک «جمع هوشمند» (Swarm) عمل میکند.
هر کدام از این مدلها تجربههای خود را از تعامل با محیط — مثلاً پاسخ دادن به سؤالات یا حل مسئله — تولید میکنند.
سپس بخشی از این تجربهها را به اشتراک میگذارند تا بقیه مدلها بتوانند از آنها یاد بگیرند.
در واقع، SAPO دنیایی از مدلهای زبانی کوچک (Small LMs) میسازد که با هم مثل یک جامعهی یادگیرنده همکاری میکنند.
«Swarm» دقیقاً چیست؟
تصور کنید مجموعهای از هزاران مدل زبانی کوچک داریم، هرکدام روی سختافزار متفاوتی اجرا میشوند — از لپتاپهای خانگی گرفته تا سرورهای کوچک.
این مجموعه همان «Swarm» است: شبکهای غیرمتمرکز از عاملها (agents) که میتوانند:
داده و تجربههای خود را به اشتراک بگذارند،
از تجربههای دیگران یاد بگیرند،
بدون نیاز به هماهنگی مرکزی کار کنند.
در SAPO، هر Node وظیفهی خودش را دارد: سؤالاتی میگیرد، پاسخهایی تولید میکند (به این پاسخها Rollout میگویند)، و آنها را با بقیه به اشتراک میگذارد.
به این ترتیب، اگر یک مدل به کشف یا راهحل جدیدی برسد — مثلاً یاد بگیرد چطور یک مسئلهی منطقی خاص را حل کند — بقیه هم میتوانند از آن تجربه بهره ببرند.
این همان چیزی است که نویسندگان از آن به عنوان «گسترش لحظههای آها (Aha Moments) در شبکه» یاد میکنند.
SAPO چطور کار میکند؟
بیایید مراحلش را به زبان ساده ببینیم:
هر مدل مجموعهای از سؤالات (Tasks) میگیرد — مثلاً از حوزههایی مثل منطق، ریاضی، یا حل پازل.
مدل پاسخهای خودش را تولید میکند (Rollouts).
بخشی از این Rolloutها را با دیگران به اشتراک میگذارد (Share).
هر مدل، در کنار تجربههای خودش، بخشی از تجربههای دیگران را نیز انتخاب میکند تا از آنها یاد بگیرد (Sample).
در نهایت، با استفاده از الگوریتمهای یادگیری تقویتی (مثل PPO یا GRPO)، سیاست خود (Policy) را بهروزرسانی میکند.
این چرخه بارها تکرار میشود، و در نتیجه، کل شبکه با هم رشد میکند.
نکتهی کلیدی SAPO این است که هیچ نیازی به هماهنگی مرکزی یا همزمانی کامل بین مدلها نیست.
هر Node میتواند مستقل کار کند، حتی اگر اتصالش کند باشد یا مدلش متفاوت.
چرا SAPO مهم است؟
روشهای مرسوم یادگیری تقویتی برای مدلهای بزرگ (مثل ChatGPT یا DeepSeek) معمولاً به زیرساختهای عظیم ابری نیاز دارند.
SAPO این وابستگی را میشکند.
چون در SAPO:
مدلها ناهمگون (Heterogeneous) هستند — یعنی هر کسی میتواند با سختافزار و مدلی متفاوت شرکت کند.
ارتباطها سبک و غیرمتمرکز هستند — فقط خروجیهای متنی به اشتراک گذاشته میشوند، نه وزنهای مدل.
یادگیری خودسازمانده (Self-Organized) است — مدلها بدون هماهنگکنندهی مرکزی پیشرفت میکنند.
به بیان ساده، SAPO راهی است برای دموکراتیزه کردن یادگیری تقویتی: هر کسی با یک لپتاپ میتواند بخشی از یک شبکهی آموزش جمعی باشد.
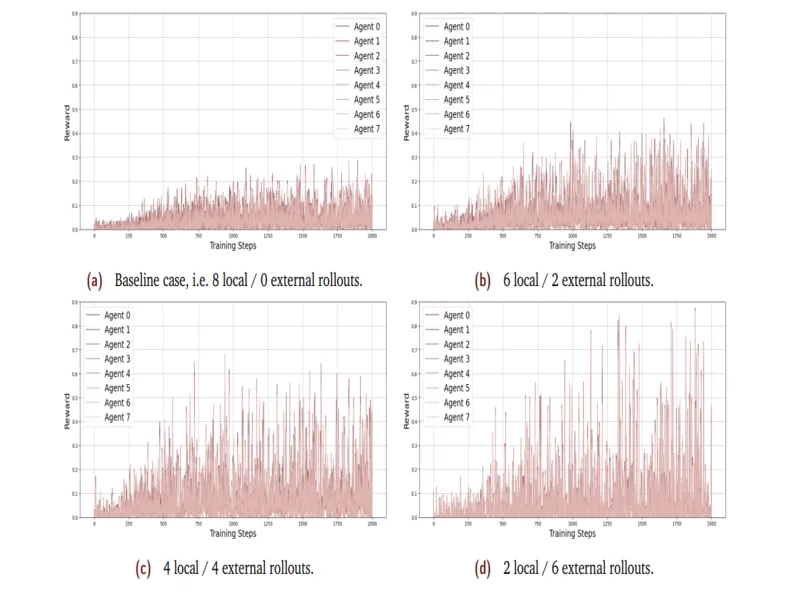
آزمایشها: یادگیری هزاران مدل های زبانی باهم
تیم Gensyn برای آزمودن SAPO مجموعهای از آزمایشها با مدلهای کوچک Qwen2.5 انجام داد (هر مدل حدود ۵۰۰ میلیون پارامتر داشت).
آنها از دیتاستی به نام ReasoningGym استفاده کردند — مجموعهای از مسائل ریاضی، منطقی و انتزاعی که پاسخ درستشان قابلبررسی است.
مدلهای زبانی در گروههای مختلف آموزش دیدند:
- فقط از تجربهی خودشان (بدون اشتراک)
- با ترکیب Rolloutهای خود و دیگران، در نسبتهای مختلف (مثلاً ۶ داخلی / ۲ خارجی، یا ۴ داخلی / ۴ خارجی)
نتیجه جالب بود:
وقتی مدلها نیمی از تجربههای خود و نیمی از تجربههای دیگران را استفاده کردند، عملکردشان ۹۴٪ بهتر از حالت بدون اشتراک بود!
این یعنی اشتراک تجربه نه تنها باعث یادگیری سریعتر شد، بلکه کیفیت کلی پاسخها هم افزایش یافت.
درسهای جالب از نتایج
- توازن مهم است.
اگر مدلها بیش از حد به Rolloutهای دیگران تکیه کنند، یادگیری ناپایدار میشود (چون ممکن است از مدلهای ضعیفتر الگو بگیرند).
ولی وقتی توازن بین تجربهی شخصی و اشتراکگذاشتهشده برقرار باشد، کل شبکه هماهنگتر و مؤثرتر رشد میکند. تأثیر جمعی واقعی است.
وقتی یکی از مدلها مسئلهای را حل میکند، دیگران میتوانند از همان تجربه بهره ببرند — بدون نیاز به بازآموزی مستقیم.یادگیری ناپیوسته اما پیشرونده است.
در برخی پیکربندیها، تیم مشاهده کرد که عملکرد مدلها نوسان دارد: گاهی جهش ناگهانی، گاهی افت موقتی.
این رفتار شبیه پویاییهای یادگیری اجتماعی در انسانهاست.
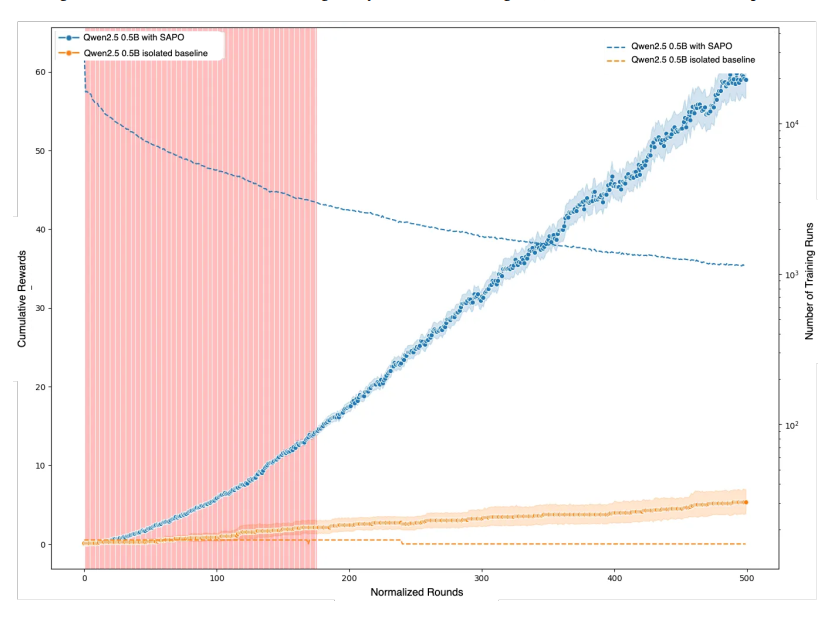
تجربهی واقعی در دنیای باز
برای آزمون SAPO در شرایط واقعی، Gensyn یک دمو باز برگزار کرد.
هزاران کاربر در شبکهی Gensyn RLSwarm شرکت کردند و مدلهای کوچک خود را روی سختافزارهای گوناگون اجرا کردند.
هر مدل در پایان هر دور از آموزش، توسط یک «قاضی» مرکزی ارزیابی میشد: قاضی سؤالی میداد، مدل پاسخ میداد، و امتیازش ثبت میشد.
نتیجه؟
مدلهایی که در Swarm شرکت کرده بودند، پس از حدود ۱۷۵ دور آموزش، به طور معنیداری بهتر از مدلهایی شدند که بهصورت انفرادی آموزش میدیدند.
البته مدلهای قویتر (مثل Qwen3) از این همکاری سود کمتری بردند — چون خودشان به اندازهی کافی قوی بودند.
اما برای مدلهای متوسط، یادگیری جمعی تفاوت چشمگیری ایجاد کرد.
نتیجه گیری
الگوریتم Swarm sAmpling Policy Optimization (SAPO)، یک روش کاملاً غیرمتمرکز و ناهمگام برای پسآموزش مدلهای زبانی با استفاده از «بهاشتراکگذاری تجربیات RL» بین چند گره است؛ در آزمایشهای کنترلشده نشان داده شده که ترکیب مناسبی از اشتراک تجربه (مثلاً ترکیب ۴ دسته داخلی / ۴ دسته اشتراکی) تقریباً ۹۴٪ بهبود کلی پاداش نسبت به حالت بدون اشتراک تجربه ایجاد میکند.
با این حال، اشتراک بیش از حد تجربیات خارجی (مثلاً ۲ داخلی / ۶ خارجی) میتواند یادگیری را ناپایدار کند و منجر به فراموشی یا نوسان شود.
بهعلاوه، مزایای SAPO بیشتر در مدلهای «میانبُرد» مشاهده شدهاند تا مدلهای بزرگتر که به اشتراک شبکهای کمتر حساساند.
در نهایت، این روش نشان میدهد که «تجربه مشترک» میتواند به عنوان راهکار مقیاسپذیر و عملی برای افزایش توان مدلهای زبانی در استدلال و یادگیری، خصوصاً در محیطهای پراکنده و ناهمگون، عمل کند

{kind=link}
بدون دیدگاه