
R-Zero مدل زبانی بزرگ با یادگیری خودتکاملی از صفر داده
این مقاله روش نوین یادگیری خودتکاملی هوش مصنوعی را بررسی میکند. چارچوب R-Zero توانایی استدلال مدلهای زبانی را بدون نیاز به دادههای برچسبخورده انسانی افزایش میدهد.
در سالهای اخیر، مدلهای زبانی بزرگ (LLM) تحول بزرگی در دنیای هوش مصنوعی ایجاد کردهاند. این مدلها میتوانند زبان طبیعی را درک کنند، متن تولید کنند و حتی در استدلالهای پیچیده مشارکت داشته باشند. با این حال، پژوهشگران همواره با چالش نیاز به دادههای برچسبخورده روبهرو بودهاند؛ فرآیندی زمانبر و پرهزینه که ظرفیت رشد مدلهای هوش مصنوعی را محدود میکند.
برای رفع این مشکل، پژوهشگران Tencent AI Lab و دانشگاه واشنگتن در سنتلوئیس چارچوبی نوین به نام R-Zero معرفی کردهاند. این چارچوب به مدلها امکان میدهد بدون نیاز به دادههای انسانی آموزش ببینند و گامی بزرگ به سوی یادگیری خودتکاملی هوش مصنوعی و توسعه هوش مصنوعی مولد بردارند.
معرفی چارچوب R-Zero
یکی از بزرگترین چالشهای یادگیری خودتکاملی هوش مصنوعی، وابستگی به دادههای برچسبخورده و گسترده است؛ دادههایی که آموزش مدلها را طولانی و پرهزینه میکنند. R-Zero این مشکل را با طراحی یک چارچوب خودگردان حل میکند.
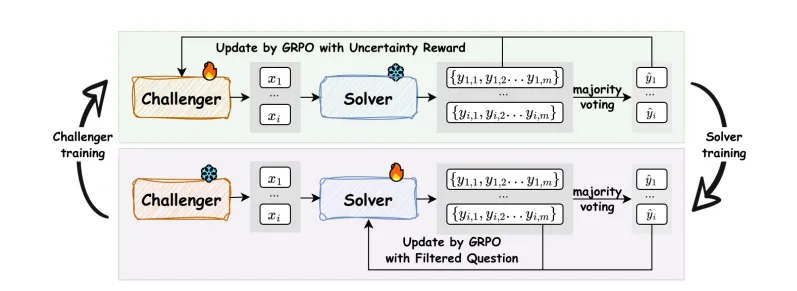
در این چارچوب یادگیری خودتکاملی هوش مصنوعی دو مدل مستقل با یکدیگر تعامل میکنند:
Challenger (چالشگر): این مدل پرسشهای سخت و چالشبرانگیز تولید میکند؛ پرسشهایی که دقیقاً در مرز تواناییهای مدل دیگر قرار دارند.
Solver (حلکننده): این مدل تلاش میکند با پاسخ به پرسشها، قدرت استدلال و دانش خود را ارتقا دهد.
چالشگر و حلکننده در یک حلقه خودتکاملی بهطور پیوسته رشد میکنند. آنها با تولید خودکار داده و تعامل مداوم، توانایی استدلال مدل نهایی را گامبهگام افزایش میدهند.
یادگیری خودنظارتی و یادگیری بدون داده برچسبخورده
یکی از ویژگیهای کلیدی R-Zero، یادگیری خودتکاملی هوش مصنوعی است. در این روش، مدل بدون تکیه بر دادههای برچسبخورده و تنها با استفاده از دادههایی که خودش تولید میکند، آموزش میبیند.
از این لینک میتوانید جواب سوال (آیا ممکن است یک مدل هوش مصنوعی بدون حتی یک سوال انسانی یا دیتای آموزشی، یاد بگیرد که چطور استدلال کند؟) را بیابید.
در هر چرخه، Challenger پرسشهای تازهای میسازد و Solver تلاش میکند به آنها پاسخ دهد. پرسشها و پاسخهای بهدستآمده به مجموعهای از دادههای آموزشی جدید تبدیل میشوند و مدل در دور بعدی با همین دادهها دوباره آموزش میبیند.
این روند، نیاز به دخالت انسانی را بهطور کامل حذف میکند و به مدلهای هوش مصنوعی اجازه میدهد به شکلی خودکار و تدریجی تواناییهایشان را ارتقا دهند.
نقش یادگیری خودتکاملی هوش مصنوعی در چارچوب R-Zero
چارچوب R-Zero از الگوریتم یادگیری تقویتی هوش مصنوعی Group Relative Policy Optimization (GRPO) بهره میگیرد؛ الگوریتمی که بهطور ویژه برای آموزش مدلهای زبانی بزرگ طراحی شده است. این الگوریتم به Challenger و Solver امکان میدهد عملکردشان را بهصورت مستمر بهبود دهند.
در هر چرخه، Challenger پرسشهایی تولید میکند که بیشترین عدمقطعیت را برای Solver ایجاد میکنند. سپس Solver با تلاش برای پاسخگویی به این پرسشها پاداش میگیرد و توانایی استدلال خود را ارتقا میدهد.
این تعامل پویا یک چرخهی تکاملی میسازد که بهطور مداوم دانش و قدرت استدلال مدلهای هوش مصنوعی را تقویت میکند.
بهبود استدلال ریاضی و قابلیتهای استدلالی مدلهای بزرگ
در آزمایشهای انجام شده، مدلهای آموزشدیده با R-Zero عملکرد چشمگیری در استدلالهای پیچیده ریاضی و دیگر معیارهای استدلال عمومی از خود نشان دادند. برای مثال، مدل Qwen3-4B-Base پس از چند مرحله آموزش با روش R-Zero، جهشی قابل توجه در بنچمارکهای ریاضی تجربه کرد و توانست مسئلههای چندمرحلهای را به شکلی دقیقتر حل کند.
این نتایج به وضوح نشان میدهند که تولید داده خودکار و یادگیری خودتکاملی میتوانند کیفیت و دقت استدلالهای هوش مصنوعی مولد را به شکل قابل توجهی بهبود بخشند، به طوری که مسیر توسعه مدلهای هوش مصنوعی پیچیدهتر و قدرتمندتر را هموار میکنند.
مزایای کلیدی چارچوب R-Zero
- خودگردان و بدون نیاز به داده برچسبخورده انسانی
- بهره گیری از الگوریتم یادگیری تقویتی پیچیده برای تولید و حل سوالات هوش مصنوعی
- بهبود قابل توجه در استدلال ریاضی و عمومی
- قابلیت تعمیم به حوزههای مختلف استدلال
- مناسب برای انواع مدلهای زبانی بزرگ
چشمانداز آینده یادگیری خودتکاملی هوش مصنوعی مولد
مسیر جدیدی را برای آموزش مدل های زبان باز کرده اند که می توانند به صورت مستقل و بدون نیاز به داده های انسانی آموزش ببینند و به تدریج توانایی های خود را گسترش دهند.این این مسیر می تواند به ساخت هوش مصنوعی مولدی با قدرت استدلال و خود آموزشی بالا منجر شود که جامعه هوش مصنوعی به سوی دست یابی به هوش فوق انسانی هدایت کند.
جمعبندی
R-Zero را میتوان یکی از گامهای بزرگ در مسیر آموزش مدلهای زبانی بزرگ بدون داده انسانی دانست. این چارچوب نشان داده است که:
- آموزش بدون دادههای برچسبخورده انسانی امکانپذیر است.
- یادگیری خودتکاملی هوش مصنوعی و تولید داده خودکار میتوانند توانایی استدلال مدلها را افزایش دهند.
- بهبود قابلتوجه در استدلال در مدلهای زبانی و بهبود استدلال ریاضی با هوش مصنوعی در عمل محقق شده است.
البته چالشهایی همچنان وجود دارند؛ بهویژه کاهش کیفیت دادههای خودتولید. اما با افزودن نقش Verifier و توسعه رویکردهای ترکیبی، این محدودیتها قابل حل خواهند بود. R-Zero نشان میدهد که آینده آموزش مدلها نه در دادههای انسانی، بلکه در خودتکاملی و استقلال هوش مصنوعی رقم خواهد خورد.

{kind=link}
بدون دیدگاه