
مقدمهای بر NLP و نقش یادگیری عمیق در تحول درک زبان انسان
پردازش زبان طبیعی یا NLP شاخهای گسترده از هوش مصنوعی است که بر توانمندسازی رایانهها برای درک، تفسیر و تولید زبان انسانی به شیوهای معنادار تمرکز دارد.
NLP از دههٔ ۱۹۵۰ میلادی آغاز شد و از سیستمهای سادهٔ مبتنی بر قواعد، به روشهای آماری و سپس به رویکردهای یادگیری ماشین و یادگیری عمیق امروزی تحول یافته است.
در اصل، NLP مجموعهای از وظایف و تکنیکها را شامل میشود که با هدف پر کردن شکاف میان ارتباط انسانی و درک رایانهای طراحی شدهاند. از جمله این وظایف میتوان به موارد زیر اشاره کرد:
تحلیل احساسات (Sentiment Analysis)
شناسایی موجودیتهای نامدار (Named Entity Recognition)
برچسبگذاری اجزای کلام (Part-of-Speech Tagging)
ترجمه ماشینی (Machine Translation)
خلاصهسازی متن (Text Summarization)
پاسخ به پرسشها (Question Answering)
تشخیص گفتار (Speech Recognition)
پیشرفت شگفتانگیز یادگیری عمیق (Deep Learning) باعث شد ماشینها نهتنها کلمات را بشناسند، بلکه معنی، نیت، احساس و حتی زمینه را هم درک کنند.
در واقع، یادگیری عمیق «مغز دوم» NLP است؛ همان اتفاقی که باعث شد ترجمههای ماشینی روان شوند، چتباتها واقعیتر حرف بزنند، تحلیل احساسات دقیق شود و موتورهای جستجو بهتر بفهمند کاربر چه میخواهد.مقاله “SAPO راهی تازه برای آموزش مدلهای زبانی با یادگیری تقویتی جمعی” حتما مطالعه کنید.

چه چیزی یادگیری عمیق را در NLP قدرتمند کرد؟
چهار عامل اصلی مسیر تحول را ساختند:
دادههای عظیم متنی
با اینترنت و شبکههای اجتماعی، مقدار داده آموزشی چند صد برابر شد.سختافزارهای قوی (GPU/TPU)
مدلهای بسیار بزرگ قابل آموزش شدند.معماریهای عصبی جدید
از RNN و LSTM تا Transformer و BERTیادگیری توزیعی (Embeddings)
کلمات به بردارهای معنیدار تبدیل شدند، نه فقط نشانههای خشک.
هوش مصنوعی NLP و یادگیری عمیق
یادگیری عمیق زیرمجموعهای از هوش مصنوعی است که از شبکههای عصبی چندلایه برای یادگیری الگوها و تصمیمگیری استفاده میکند.
این رویکرد در حوزههایی مانند بینایی ماشین، تشخیص گفتار و بهویژه NLP عملکردی فراتر از روشهای کلاسیک ارائه داده است
معماریهای اصلی NLP در یادگیری عمیق:
- MLP: شبکه پیشخور ساده برای طبقهبندی.
CNN: استخراج ویژگیهای مکانی از دادهها (مانند کلمات در جمله).
RNN/LSTM: مدلسازی دنبالهای برای متن و گفتار.
Autoencoder: فشردهسازی و بازسازی داده بدون برچسب.
GAN: تولید دادههای مصنوعی مانند جملات جدید یا متنهای شبیه واقعیت.
- Transformer :مبتنی بر مکانیزم Attention است، یعنی «توجه انتخابی».
چرا یادگیری عمیق در NLP یک انقلاب واقعی ایجاد کرد؟
در ظاهر، زبان چیزی جز مجموعهای از کلمات کنار هم نیست، اما در عمل، زبان یک سیستم زنده، زمینهمحور و پیچیده است.
روشهای سنتی در NLP فقط سطح کلمات را میدیدند و نمیتوانستند معنی پنهان در ساختار جملهها را استخراج کنند.
اینجاست که یادگیری عمیق وارد شد و مشکل را از ریشه حل کرد.
آشنایی با معماریهای اصلی یادگیری عمیق در NLP
برای اینکه بفهمیم چرا NLP مدرن اینقدر قدرتمند است، باید با «مغزهای محاسباتی» پشت آن آشنا شویم. این مغزها همان معماریهای شبکههای عصبی هستند که هر کدام برای نوع خاصی از پردازش زبان طراحی شدهاند.
مقاله مرتبط با عنوان “ASI‑ARCH: لحظهی AlphaGo در طراحی خودکار معماری شبکه عصبی” را حتما مطالعه کنید.
در این بخش، مهمترین معماریها را به زبان ساده و کاربردی معرفی میکنیم.
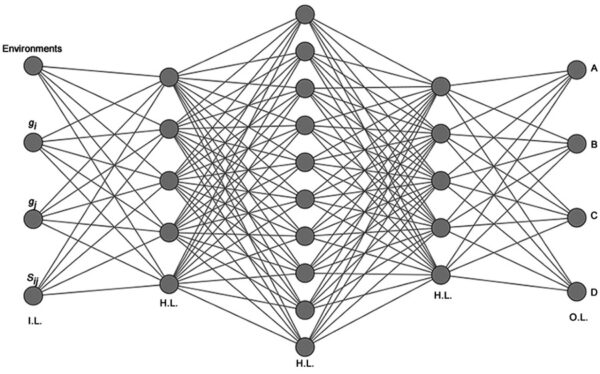
1. پرسپترون چندلایه (MLP) در NLP
ساختارMLP در NLP
متشکل از لایه ورودی، یک یا چند لایه پنهان (Hidden Layers) و لایه خروجی.
هر نود (نورون) در یک لایه به تمام نورونهای لایه بعدی وصل است (Fully Connected / Dense Layer).
هر نورون یک وزن (Weight) و بایاس (Bias) دارد و از تابع فعالسازی مثل ReLU یا Sigmoid استفاده میکند.
| ویژگی | توضیح |
|---|---|
| ساختار | لایه ورودی → چند لایه مخفی → لایه خروجی |
| قدرت | مناسب طبقهبندی ساده متن |
| محدودیت | نمیتواند توالی و ترتیب کلمات را درک کند |
کاربرد:
تشخیص اسپم یا غیر اسپم
(فقط نگاه میکند چه کلماتی هستند، نه ترتیبشان)
2. شبکه عصبی کانولوشنی (CNN) در NLP
در ابتدا CNNها برای بینایی کامپیوتر طراحی شدند.اما بعدها مشخص شد که برای فهم الگوهای محلی در متن هم عالی عمل میکنند.
ساختارCNN:
لایه کانولوشن (Convolution Layer): فیلترهایی روی تصویر حرکت میکنند تا ویژگیهای محلی (لبه، بافت) استخراج شوند.
لایه Pooling: (معمولاً MaxPooling) برای کاهش ابعاد و حفظ ویژگیهای مهم.
لایه Fully Connected: بعد از استخراج ویژگیها برای طبقهبندی نهایی.
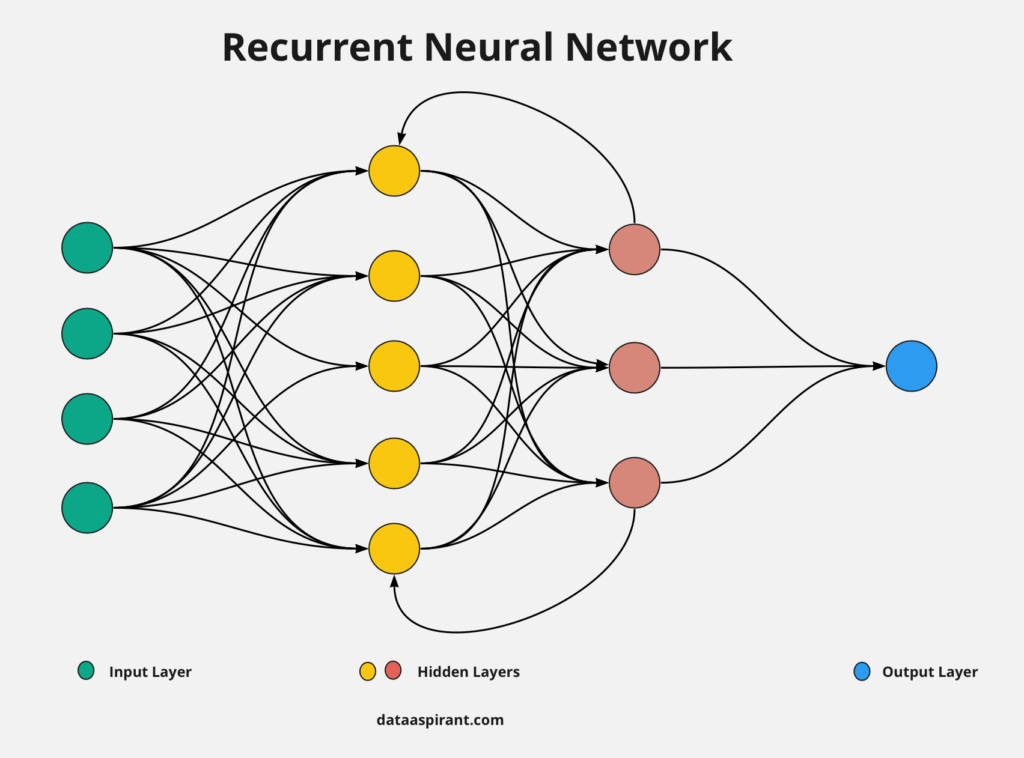
3. شبکههای بازگشتی (RNN) در NLP
RNN یک شبکه عصبی است که با داشتن حافظه داخلی، وابستگیهای زمانی بین عناصر یک دنباله مثل کلمات در متن را درک میکند.
ساختار RNN:
هر نود علاوه بر دریافت ورودی فعلی، حالت قبلی (Hidden State) را دریافت میکند.
این ساختار اجازه میدهد که وابستگیهای زمانی را درک کند.
مشکل اصلی RNN کاهش یا انفجار گرادیان (Vanishing/Exploding Gradient) هنگام آموزش روی دنبالههای طولانی بود، یعنی شبکه نمیتوانست وابستگیهای بلندمدت را یاد بگیرد.
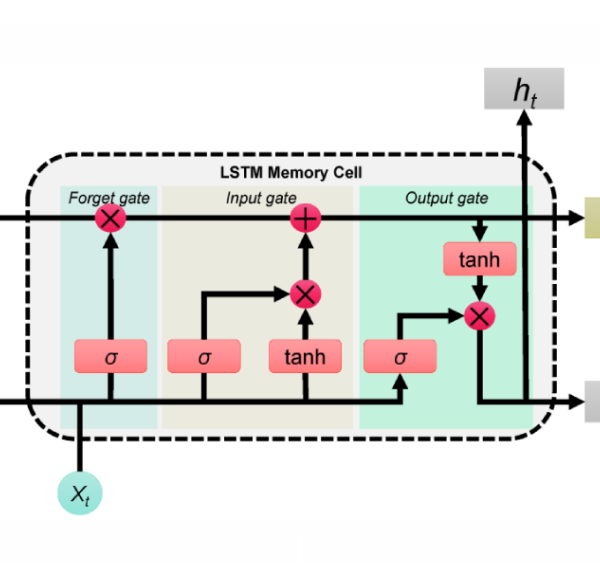
4. شبکه LSTM (Long Short-Term Memory)
LSTM نوعی RNN است که با استفاده از دروازهها، اطلاعات مهم را در طول دنباله حفظ و اطلاعات غیرضروری را فراموش میکند تا وابستگیهای بلندمدت را بهتر یاد بگیرد.
ساختار LSTM در NLP:
LSTM نسخه ارتقایافتهی RNN است با حافظه طولانیمدت.
این معماری دیگر وابستگیهای دور را از دست نمیدهد.
شامل سه دروازه (Gate):
Forget Gate: تصمیم میگیرد چه اطلاعاتی از حافظه پاک شود.
Input Gate: چه اطلاعاتی وارد حافظه شود.
Output Gate: چه اطلاعاتی از حافظه به خروجی برود.
این ساختار باعث حفظ وابستگیهای بلندمدت در دادههای ترتیبی میشود.
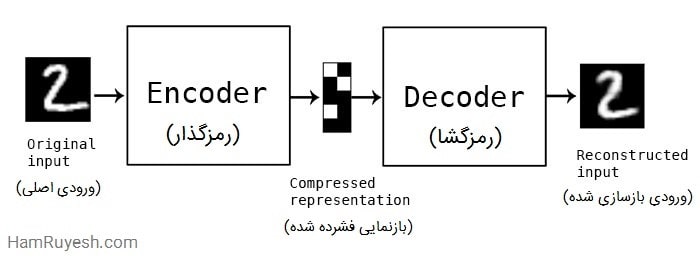
5. Autoencoder
Autoencoder شبکهای است که دادهها را به یک نمایش فشرده تبدیل و سپس تلاش میکند همان دادهها را بازسازی کند.
ساختار Autoencoder:
شامل دو بخش:
Encoder: داده را به یک نمایش فشرده (Latent Vector) تبدیل میکند.
Decoder: تلاش میکند داده اصلی را بازسازی کند.
هدف: کمینه کردن خطای بازسازی (Reconstruction Loss).
ویژگیها:
کاهش ابعاد، استخراج ویژگیهای مهم.
نوع پیشرفته: Variational Autoencoder (VAE) که به تولید داده جدید هم میپردازد.
6. GAN (Generative Adversarial Networks)
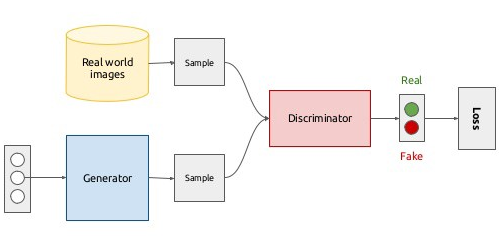
GAN شامل دو شبکه مخالف است: مولد که دادههای مصنوعی میسازد و تشخیصدهنده که تلاش میکند واقعی یا مصنوعی بودن آنها را تشخیص دهد.
ساختارGAN:
شامل دو شبکه مخالف:
Generator (مولد): تلاش میکند دادههای واقعی مانند دادههای آموزشی بسازد.
Discriminator (تشخیصدهنده): تلاش میکند داده واقعی را از داده مصنوعی تشخیص دهد.
آموزش به صورت بازی صفر-جمعی: Generator سعی میکند Discriminator را فریب دهد.
7. معماری Transformer
نقطه عطف بزرگ در NLP
ظTransformer باعث شد NLP از مرحله «فهم ساده» وارد مرحله درک عمیق و واقعی زبان شود.
این معماری مبتنی بر مکانیزم Attention است، یعنی «توجه انتخابی».
مدل یاد میگیرد روی کدام بخش جمله تمرکز کند.
| چرا فوقالعاده است؟ |
|---|
| نیازی به پردازش ترتیبی ندارد (برخلاف RNN/LSTM) |
| سریعتر آموزش میبیند |
| وابستگیهای طولانی را عالی میفهمد |
| مقیاسپذیر است (مدلهای بسیار بزرگ) |
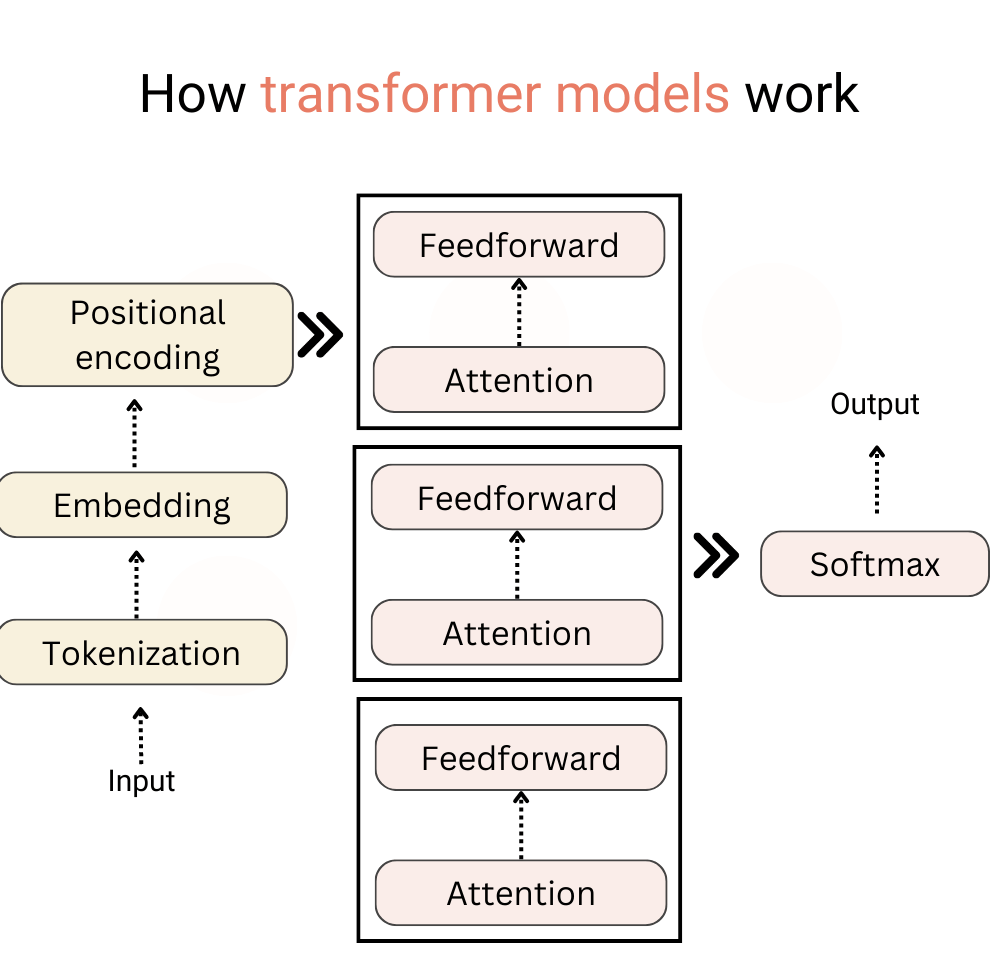
معماری ترنسفورمر — کامل و واضح (رمزگذار / رمزگشا در NLP)
ترنسفورمر یک معماری شبکه عصبی است که پردازش توالیها را بدون RNN یا LSTM ممکن میکند، با تکیه بر مکانیزم توجه (Self-Attention).
ایدهٔ اصلی: هر کلمه یا توکن در جمله، میتواند به همهٔ کلمات دیگر نگاه کند و یاد بگیرد که کدامیک برای فهم یا تولید متن مهم هستند.
این کار را با مکانیزم توجه (Attention) انجام میدهد و برخلاف مدلهای قدیمی مثل RNN، لازم نیست کلمات را یکییکی و به ترتیب پردازش کند.
ایدهٔ توجه (Attention)
وقتی مدل میخواهد یک کلمه را پردازش کند، به بقیه کلمات نگاه میکند و تصمیم میگیرد کدام کلمات بیشترین اهمیت را دارند.
این نگاه «چقدر هر کلمه روی کلمهی مورد نظر تاثیر دارد» را وزندهی میکند.
مزیت: مدل میتواند روابط طولانی بین کلمات را به راحتی یاد بگیرد.
مقاله “ترکیب RAG و Fine-Tuning : نبرد دو روش برای آموزش مدلهای زبانی بزرگ” را حتما مطالعه کنید.
ساختار کلی ترنسفورمر
1.Encoder(رمزگذار):
کار Encoder: دریافت جملهی ورودی و تبدیل آن به مجموعهای از بردارها که معنی و زمینهی هر کلمه را نمایش میدهند.
- هر لایه Encoder شامل:
- Self-Attention: هر کلمه به همهی کلمات دیگر نگاه میکند.
- Feed-Forward Network: هر کلمه به صورت مستقل پردازش غیرخطی میشود.
- لایههای کمکی: مثل LayerNorm و اتصال باقیمانده برای آموزش پایدار و بهتر.
- معمولا چند لایه Encoder روی هم چیده میشوند تا بردارهای خروجی غنیتر شوند.
2. Decoder (رمزگشا)
- کار Decoder: تولید جمله یا توالی خروجی، مثلاً ترجمه یا خلاصه.
در هر مرحله:
Masked Self-Attention: کلمات قبلی را نگاه میکند اما آینده را نمیبیند (تا جلوی تقلب گرفتن مدل از آینده گرفته شود).
Encoder-Decoder Attention: به بردارهای خروجی Encoder نگاه میکند تا اطلاعات منبع را بازیابی کند.
Feed-Forward Network: هر کلمه پردازش نهایی میشود و توکن بعدی پیشبینی میشود.
تولید خروجی معمولاً کلمه به کلمه انجام میشود و مدل هر بار از کلمات تولیدشده قبلی استفاده میکند.
NLP و تولد چتباتهای مدرن
پس از معرفی ترنسفورمر و مکانیزم Attention، در واقع دریچهای جدید به دنیای زبان باز شد. پیش از این، چتباتها بسیار محدود بودند: معمولاً پاسخهای آماده داشتند یا فقط الگوهای سادهای مثل «اگر این سؤال بود، آن جواب بده» را دنبال میکردند. اما با یادگیری عمیق و مدلهای بزرگ زبانی مثل GPT یا BERT، اتفاقی شگفتانگیز افتاد: ماشینها دیگر فقط کلمات را تشخیص نمیدهند، بلکه معنی، زمینه و حتی لحن گفتگو را میفهمند.
مغز چتباتها: چگونه جوابها ساخته میشوند؟
1.توکنسازی (Tokenization):
ابتدا متن ورودی به قطعات کوچک (توکنها) تقسیم میشود، مثلاً هر کلمه یا بخش کوچکی از کلمه.
2.تبدیل به بردار (Embeddings):
هر توکن به یک بردار عددی معنیدار تبدیل میشود که مدل بتواند روابط بین کلمات را یاد بگیرد.
3.پردازش با ترنسفورمر:
Self-Attention: هر کلمه نگاه میکند که کدام کلمات دیگر برای درک جمله مهم هستند.
مدل قادر است وابستگیهای بلندمدت را درک کند؛ مثلاً پاسخ به یک سؤال ممکن است به جملهای باشد که چند جمله قبل گفته شده است.
4.رمزگشا (Decoder):
مدل با توجه به زمینه و یادگیری قبلی، کلمه بعدی را تولید میکند تا جمله روان و طبیعی ساخته شود.نتیجه این فرآیند، چتباتهایی است که میتوانند پاسخهای خلاقانه، طبیعی و متناسب با زمینه گفتگو بدهند.
کاربردهای عملی چتباتها
چتباتهای مدرن NLP امروز در بسیاری از زمینهها حضور دارند:
پشتیبانی مشتری: پاسخ به پرسشهای متداول و کمک سریع به کاربران.
آموزش و یادگیری: پاسخ به سؤالهای دانشآموزان و شبیهسازی استاد.
خلاقیت و تولید محتوا: نوشتن متن، داستان، شعر یا حتی کد برنامهنویسی.
سلامت روان و مشاوره اولیه: گفتگوهای حمایتی و تشویق به بیان احساسات.
تمام این قابلیتها نتیجه مستقیم پیشرفتهای یادگیری عمیق در NLP است. بدون شبکههای بزرگ زبانی و ترنسفورمرها، چتباتها هرگز نمیتوانستند چنین تعامل طبیعی و معناداری داشته باشند.

نتیجهگیری و چشمانداز آینده NLP و چتباتها
پردازش زبان طبیعی (NLP) از زمان تولد خود در دهه ۱۹۵۰ مسیر طولانی و تحولآفرینی را طی کرده است؛ از سیستمهای ساده مبتنی بر قواعد تا مدلهای آماری و یادگیری ماشین، و نهایتاً یادگیری عمیق که اکنون هستهی توانمندی چتباتها و سیستمهای هوشمند است.
یادگیری عمیق، به ویژه معماریهای ترنسفورمر و مدلهای بزرگ زبانی، توانست ماشینها را از یک پردازشکننده سطحی کلمات به یک درککننده معنا، زمینه و نیت انسانی تبدیل کند. این تحول نه تنها کیفیت ترجمه ماشینی، تحلیل احساسات و پاسخ به پرسشها را بهبود داده، بلکه زمینه را برای تولید چتباتهایی فراهم کرده است که میتوانند تعاملات طبیعی، خلاقانه و انسانی داشته باشند.
گسترش Multimodal AI: ترکیب متن، تصویر، صدا و حتی حرکت برای ایجاد تعاملات غنیتر و طبیعیتر.
چتباتهای هوشمندتر و شخصیتر: توانایی یادگیری از تعاملات فردی و تطبیق پاسخها با سبک و لحن کاربر.
بهبود فهم زبان پیچیده: مدلها قادر خواهند بود استعاره، طنز، کنایه و زمینه فرهنگی را بهتر درک کنند.
کاربردهای روزافزون: از آموزش و مراقبت سلامت گرفته تا تولید محتوا و مشاوره، NLP آیندهای چندوجهی و گسترده دارد.
در نهایت، NLP و یادگیری عمیق نه تنها ابزارهای تکنولوژیک هستند، بلکه دروازهای برای درک عمیقتر انسان و تعامل طبیعیتر با ماشینها محسوب میشوند؛ چیزی که در آینده نزدیک، زندگی دیجیتال و تعاملات روزمره ما را به شکل بنیادین متحول خواهد کرد.
جمعبندی
پردازش زبان طبیعی (NLP) امروز دیگر صرفاً یک حوزهی تحقیقاتی در هوش مصنوعی نیست، بلکه پلی میان تفکر انسانی و درک ماشینی است. از نخستین تلاشهای مبتنی بر قواعد تا ظهور معماریهای یادگیری عمیق، مسیر NLP همواره بهسمت فهم واقعیتر زبان انسان حرکت کرده است.
ظهور شبکههای عصبی عمیق، بهویژه معماری ترنسفورمر (Transformer) و مدلهای بزرگ زبانی، نقطهعطفی در این مسیر بود؛ چراکه به ماشینها توانایی درک معنا، زمینه، نیت و احساسات انسانی را بخشید. اکنون سیستمهایی مانند چتباتهای مدرن، ترجمهگرهای هوشمند و ابزارهای تولید محتوا نهتنها متن را تحلیل میکنند، بلکه آن را میفهمند و بازتولید میکنند.
آیندهی NLP روشنتر از همیشه است — آیندهای که در آن، تعامل انسان و ماشین به شکلی طبیعی، پویا و چندوجهی (متنی، صوتی، تصویری) انجام میشود.
در این مسیر، یادگیری عمیق نهتنها موتور محرک NLP است، بلکه کلید درک عمیقترِ خودِ انسان توسط فناوری محسوب میشود.

{kind=link}
بدون دیدگاه