
FineVision: دادههای باز، تمام چیزی که نیاز دارید
در سالهای اخیر، مدلهای زبانی-تصویری (VLM) تحول بزرگی در درک دادههای چندرسانهای ایجاد کردهاند. با این حال، جامعه پژوهشی متنباز با چالش بزرگی روبروست: دادههای چندوجهی موجود پراکنده، ناسازگار و اغلب آلوده هستند. این مسئله شکاف عمیقی بین مدلهای متنباز و انحصاری ایجاد کرده و مانع پیشرفت پژوهشهای مستقل شده است.
برای حل این مشکل، FineVision را معرفی شده است — یک مجموعهداده عظیم با بیش از ۲۴ میلیون نمونه، شامل ۱۷ میلیون تصویر، ۸۹ میلیون دیالوگ و ۹.۵ میلیارد توکن متنی.
آنچه FineVision را متمایز میکند، فرآیند دقیق پالایش دادهها است:
گردآوری و یکپارچهسازی بیش از ۲۰۰ منبع داده عمومی
حذف تصاویر خراب و ناقص
استانداردسازی متون و بررسی تطابق متن و تصویر
حذف دادههای تکراری و آلوده با مقایسه با ۶۶ مجموعهداده ارزیابی
بازبینی نهایی توسط انسان برای اطمینان از دقت و تنوع
نتیجه این فرآیند، مجموعهدادهای با کیفیت است که مدلهای آموزشی را تا ۴۶٪ قویتر از رقبا کرده است. FineVision با انتشار آزاد دادهها و ابزارهایش، مسیر جدیدی برای پژوهشگران و توسعهدهندگان گشوده تا مدلهای چندوجهی دقیقتر و شفافتری بسازند.آنچه FineVision را متمایز میکند، فقط اندازهی آن نیست، بلکه فرآیند دقیق و نیمهخودکارِ پالایش دادههاست.

🧩 چگونه FineVision ساخته شد
پروژهی FineVision با یک هدف ساده اما جاهطلبانه آغاز شد:
ایجاد یک مجموعهدادهی بزرگ، متنوع و تمیز برای آموزش مدلهای زبانی-تصویری متنباز.
برای تحقق این هدف، تیم پژوهش از بیش از ۲۰۰ مجموعهدادهی عمومی استفاده کرد و آنها را در قالبی یکپارچه و قابل استفاده برای مدلهای گفتوگومحور (chat-based) تبدیل نمود.
اما مسیر ساده نبود — هر منبع داده، ساختار و قالب خاص خود را داشت. برخی شامل تصویر و توضیح کوتاه بودند، برخی مجموعهای از پرسشوپاسخهای چندمرحلهای، و بعضی دیگر شامل نمودارها، اسناد چندصفحهای یا حتی رابطهای کاربری تعاملی بودند.
🔄 فرآیند ترکیبی انسان و هوش مصنوعی
تیم FineVision برای این کار یک سیستم نیمهخودکار با نظارت انسانی (Human-in-the-loop) طراحی کرد.
در این سیستم، بخش خودکار وظیفهی جمعآوری و استانداردسازی دادهها را داشت، در حالی که بازبینهای انسانی مرحلهبهمرحله خروجی را بررسی میکردند تا اطمینان یابند که:
تمام برچسبها و توضیحات منبع بهدرستی منتقل شدهاند،
قالب مکالمهها منظم و متنوع است،
هیچ محتوای تکراری یا ناامن وجود ندارد،
و کیفیت کلی نمونهها در حد مطلوب باقی میماند.
اگر در هر مرحله ایرادی مشاهده میشد (مثلاً اشتباه در تفسیر برچسبها یا قالبهای شکننده)، سیستم اصلاح و دوباره اجرا میشد تا دادهی نهایی بینقص گردد.
💬 تبدیل دادهها به گفتوگوهای طبیعی
تمام دادهها در نهایت به شکل مکالمات طبیعی بین «کاربر» و «دستیار هوشمند» بازنویسی شدند.
برای نمونه، در دادههای پرسشوپاسخ تصویری (Visual QA)، چند سؤال دربارهی یک تصویر به گفتوگویی چندمرحلهای تبدیل شد.
در دادههای توضیح تصویر (Captioning)، توضیحات اصلی با دستورهای متنوعی مثل «این تصویر را توصیف کن» یا «به من بگو در این صحنه چه میبینی» ترکیب شد تا مدل درک بهتری از سبکهای مختلف گفتار به دست آورد.
در دادههای خاصتر مانند نمودارها، اسناد یا ریاضیات، تیم از استراتژیهای ویژهای استفاده کرد تا مفهوم و ساختار دادهها حفظ شود.
حتی دادههای مربوط به رابطهای کاربری (GUI) هم به قالبی یکپارچه تبدیل شدند تا مدلها بتوانند با دقت بیاموزند چگونه روی دکمهها، منوها یا پنجرهها تعامل کنند — دقیقاً مثل یک کاربر واقعی.
🧹 پاکسازی و استانداردسازی
برای تضمین کیفیت، فرآیند پاکسازی دادهها شامل چندین مرحلهی خودکار بود:
حذف تصاویر خراب یا ناقص،
اصلاح جهت تصویر و تبدیل آنها به حالت استاندارد RGB،
تمیزسازی متون (حذف نویسههای بیمعنی، اصلاح نشانهگذاری و نرمالسازی فرمت)،
و حذف پاسخهای بیارزش یا تکراری.
هر نمونهی متنی به حداکثر ۸۱۹۲ توکن محدود شد تا در آموزش مدلها ثبات و کارایی حفظ شود.
🚫 کنترل تکرار و آلودگی داده
برای جلوگیری از ورود دادههای تکراری یا همپوشان، FineVision از یک الگوریتم قدرتمند تشخیص شباهت تصویری به نام SSCD استفاده کرد.
این الگوریتم دادهها را در دو سطح بررسی کرد:
درونمجموعهای: حذف تصاویر بسیار مشابه در خود مجموعه.
بینمجموعهای: بررسی شباهت با ۶۶ مجموعهدادهی ارزیابی عمومی تا از نشت داده به دادههای تست جلوگیری شود.
نتیجهی این پالایش دقیق، مجموعهای تمیز و منحصربهفرد است که دقت مدلهای آموزشی را بالا میبرد و خطر نشت یا یادگیری کاذب را به حداقل میرساند.
در یک جمله: FineVision ترکیب هوش مصنوعی، دقت انسانی و اصول دادهمحور است — دادهای که نهتنها بزرگ است، بلکه قابل اعتماد و سالم است.

🔬 کاوش در FineVision
پس از ساخت و پالایش مجموعهداده، تیم پژوهش تصمیم گرفت FineVision را از جنبههای گوناگون بررسی کند تا بفهمد این مجموعه واقعاً چه ویژگیهایی دارد و چرا باعث بهبود عملکرد مدلها میشود.
در این مرحله، دادهها از سه بُعد کلیدی مورد تحلیل قرار گرفتند:
1.ترکیب و تنوع وظایف (Category Composition)
2.کیفیت مکالمات و دادهها (Turn Quality)
3.تنوع تصویری (Visual Diversity)
📚 ترکیب وظایف و موضوعات
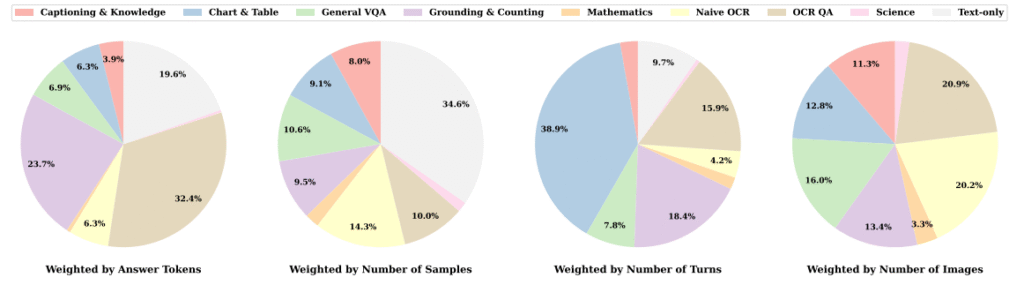
مجموعهدادهی FineVision شامل ۹ دستهی اصلی از وظایف است، از جمله:
توضیح تصویر و دانش عمومی (Captioning & Knowledge)
تحلیل نمودار و جدول (Chart & Table)
پرسشوپاسخ تصویری (VQA)
شمارش و مکانیابی اجسام (Grounding & Counting)
ریاضیات و استدلال منطقی (Mathematics)
OCR ساده و OCR پیشرفته (تشخیص متن از تصویر)
درک علمی و متون تخصصی (Science)
دادههای صرفاً متنی (Text-only)
این تقسیمبندی باعث شده FineVision از نظر نوع دادهها، تنوع بیسابقهای داشته باشد.
بهعنوان مثال، در بخش نمودار و جدول معمولاً چند سؤال متوالی دربارهی یک نمودار پرسیده میشود، که باعث ایجاد گفتوگوهای چندمرحلهای میگردد.
در مقابل، وظایف مربوط به OCR معمولاً پاسخهای بلندتر و تحلیلیتر دارند، زیرا مدل باید مفهوم کامل اسناد یا فاکتورها را درک کند.
🧠 کیفیت مکالمات
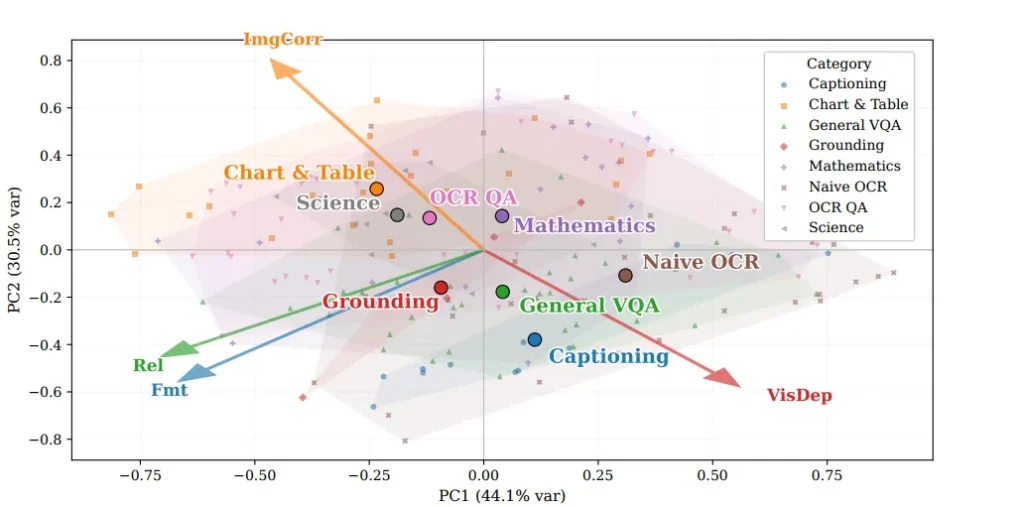
برای ارزیابی کیفیت، پژوهشگران از مدلهای زبانی بزرگ (LLMs و VLMs) بهعنوان داور استفاده کردند. هر مکالمه بر اساس چهار معیار از ۱ تا ۵ امتیاز گرفت:
1️⃣ فرمت و نظم پاسخها (Formatting)
2️⃣ ارتباط و تناسب با پرسش (Relevance)
3️⃣ وابستگی به تصویر (Visual Dependency)
4️⃣ همخوانی پرسش با تصویر (Image–Question Correspondence)
نتایج نشان داد که FineVision از نظر انسجام و تناسب موضوعی، کیفیت بسیار بالایی دارد:
بیش از ۸۵٪ از مکالمات امتیاز ۴ یا ۵ در معیار ارتباط گرفتند.
در معیار فرمت نیز ۹۷٪ از دادهها نمرهی عالی کسب کردند.
در واقع، FineVision ترکیبی از پرسشهای دقیق، پاسخهای مرتبط و ساختار متنی منظم است — چیزی که برای آموزش مدلهای هوشمند گفتوگومحور حیاتی است.
همچنین، تحلیلها نشان داد که دو ویژگی وابستگی به تصویر و همخوانی پرسش با تصویر رابطهی معکوس دارند.
یعنی برخی وظایف مثل «توصیف تصویر» بیشتر به درک کلی صحنه نیاز دارند، در حالی که وظایفی مثل «پرسش دربارهی جزئیات جدول یا موقعیت اشیاء» مستقیماً با محتوای دقیق تصویر مرتبطاند.
تنوع تصویری بینظیر
یکی از برجستهترین ویژگیهای FineVision، تنوع تصویری بالاست.
برای اندازهگیری این تنوع، پژوهشگران از دو شاخص آماری استفاده کردند:
Effective Rank (رتبهی مؤثر): نشان میدهد دادهها چهقدر از نظر مفهومی گستردهاند.
Participation Ratio (نسبت مشارکت): نشان میدهد این گستردگی تا چه حد متعادل و یکنواخت است.
نتایج نشان داد FineVision در هر دو شاخص بالاترین مقدار را میان تمام مجموعهدادههای باز (مانند Cambrian و LLaVA) دارد.
به زبان ساده، FineVision نهتنها موضوعات متنوعی را پوشش میدهد، بلکه این تنوع در میان مفاهیم مختلف بهصورت متعادل توزیع شده است.
این یعنی مدلهایی که روی FineVision آموزش میبینند، درک گستردهتر و منصفانهتری از جهان بصری پیدا میکنند — بدون وابستگی افراطی به چند نوع تصویر خاص مثل چهره یا حیوانات.
در نتیجه، FineVision فقط یک مجموعهدادهی بزرگ نیست؛ بلکه ترکیبی متعادل، باکیفیت و انسانی از دادههای متنی و تصویری است که برای آموزش مدلهای زبانی-تصویری نسل جدید طراحی شده است.
آزمایشها و نتایج FineVision
بعد از ساخت و پالایش دقیق FineVision، تیم پژوهش آن را روی مدلهای مختلف آزمایش کرد تا تأثیر واقعی این دادهها بر عملکرد مدلهای زبانی–تصویری را بسنجد.
نتیجهی کار، فراتر از انتظار بود — مدلهایی که با FineVision آموزش دیدند، در تمام آزمونها عملکرد بهتری از مدلهای متنباز رقیب نشان دادند.
🧠 مدل و تنظیمات آموزشی
تمام آزمایشها با استفاده از مدلی به نام SmolVLM انجام شد؛ یک مدل سبک با حدود ۴۶۰ میلیون پارامتر که بر پایهی معماری ترکیبی ساخته شده است:
یک بخش زبانی به نام SmolLM2 برای پردازش متن،
و یک بخش بینایی به نام SigLIP2 برای درک تصویر.
فرآیند آموزش حدود ۲۰ هزار مرحله طول کشید و روی ۳۲ کارت گرافیک H100 اجرا شد.
در این مدت، مدل تقریباً تمام مجموعهدادهی FineVision را یک بار بهطور کامل مشاهده کرد.
⚖️ مقایسه با رقبا
برای ارزیابی، تیم FineVision مدل خود را با سه مجموعهدادهی معروف مقایسه کرد:
- The Cauldron
- LLaVA-OneVision
- Cambrian-7M
نتیجه کاملاً روشن بود 👇
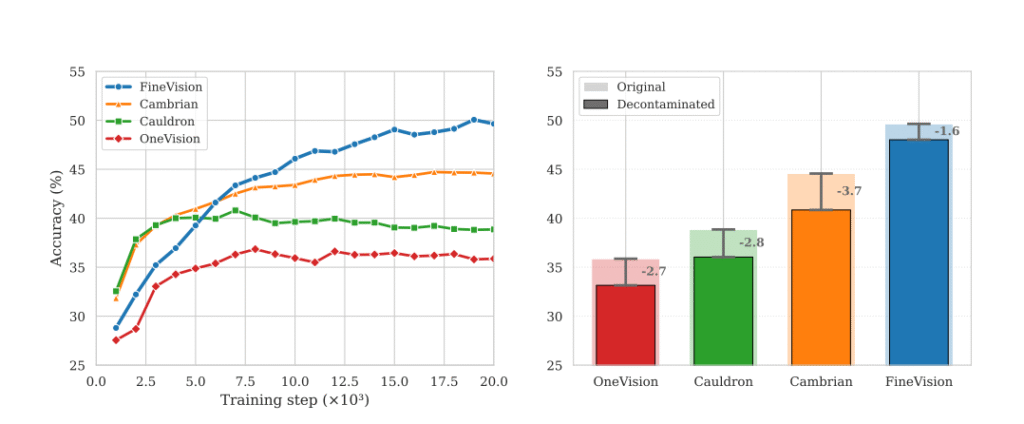
مدل آموزشدیده با FineVision در تمام ۱۱ بنچمارک عمومی — از جمله AI2D، ChartQA، DocVQA، TextVQA، ScienceQA و MMStar — بهطور میانگین:
۱۲.۷ درصد بهتر از The Cauldron،
۵.۱ درصد بهتر از Cambrian،
و ۱۴.۳ درصد بهتر از LLaVA-OneVision عمل کرد.
جالب اینکه در ابتدای آموزش، مدل FineVision کمی کندتر پیشرفت میکرد (به خاطر تنوع وظایف جدیدی که در داده وجود داشت)، اما در نیمهی دوم آموزش، با سرعت از رقبا پیشی گرفت و در نهایت به بهترین عملکرد ممکن رسید.
🧩 تأثیر پاکسازی و کنترل آلودگی
یکی از بخشهای کلیدی FineVision، کنترل دقیق آلودگی داده است — یعنی جلوگیری از وجود نمونههایی که در دادههای تست هم دیده میشوند.
وقتی تیم پژوهش همهی مجموعهدادهها را از نظر آلودگی بررسی کرد، مشخص شد که:
مجموعهدادههای دیگر بین ۲ تا ۳ درصد آلودگی دارند،
اما FineVision تنها ۱.۰۲ درصد آلودگی دارد.
پس از حذف کامل دادههای آلوده و آموزش مجدد، عملکرد مدلهای رقیب بهطور متوسط ۳ درصد کاهش یافت،
در حالی که مدل FineVision فقط ۱.۶ درصد افت جزئی نشان داد.
این نشان میدهد که برتری FineVision ناشی از کیفیت واقعی دادههاست، نه بهخاطر نشت اطلاعات از مجموعههای تست.
🖥️ قابلیتهای جدید در تعامل با رابط کاربری (GUI)
یکی از جذابترین بخشهای FineVision، حضور دادههای مربوط به رابطهای کاربری و وظایف عاملمحور است.
این نوع دادهها به مدل کمک میکنند تا رفتارهای انسانی در تعامل با نرمافزارها را یاد بگیرد — مثل کلیک، تایپ یا پیمایش صفحه.
در آزمایشی بر روی دو بنچمارک تخصصی رابط کاربری (ScreenSpot-V2 و ScreenSpot-Pro)، مدل آموزشدیده با FineVision حتی با نسخهای از مدل که چهار برابر بزرگتر بود، عملکردی برابر یا بهتر داشت.
به بیان دیگر، FineVision نهتنها دقت مدل را افزایش میدهد، بلکه توانایی تعامل هوشمند با محیطهای گرافیکی را هم به آن میآموزد — قابلیتی که در بیشتر مجموعهدادههای قبلی وجود نداشت.
✨ در مجموع، نتایج نشان دادند که FineVision بهترین عملکرد میان تمام مجموعهدادههای باز را ارائه میدهد.
این موفقیت حاصل ترکیب سه عامل کلیدی است:
1️⃣ دادههای تمیز و دقیق،
2️⃣ تنوع متعادل در وظایف و تصاویر،
3️⃣ و نظارت انسانی در هر مرحله از ساخت.

نتیجهگیری: FineVision، گامی بزرگ برای دادههای باز در هوش مصنوعی
پروژهی FineVision نقطهی عطفی در مسیر توسعهی مدلهای زبانی–تصویری متنباز است.
این پروژه نشان داد که با ترکیب هوشمندانهی اتوماسیون، بازبینی انسانی و رعایت اصول پاکسازی داده میتوان مجموعهدادهای ساخت که از بسیاری از منابع اختصاصی نیز دقیقتر و قابل اعتمادتر باشد.
FineVision با گردآوری و یکپارچهسازی بیش از ۲۰۰ منبع عمومی، ساختار گفتوگومحور منسجمی ایجاد کرده که تمام حوزههای کلیدی درک تصویری را در بر میگیرد — از توضیح تصویر و پاسخ به پرسشهای بصری گرفته تا درک اسناد، OCR و تعامل با رابطهای کاربری (GUI).
در این مسیر، تیم پژوهش مجموعهای از روشهای پیشرفتهی پاکسازی را به کار گرفت:
حذف دادههای تکراری و آلودگیهای بین مجموعهها،
بازبینی دستی نمونهها برای اطمینان از دقت و تنوع،
و استفاده از مدلهای خودکار برای تشخیص ناسازگاریها و خطاها.
نتیجه این تلاشها، دادهای بود که آموزش مدلها را شفافتر، قابل بازتولیدتر و اخلاقیتر کرد.
🌍 آیندهی FineVision
هدف از انتشار آزاد FineVision، تنها عرضهی یک دیتاست نیست؛ بلکه ایجاد پایهای شفاف و قابل گسترش برای پژوهشهای آینده در حوزهی هوش مصنوعی چندوجهی است.
تیم توسعهدهنده قصد دارد در مراحل بعدی:
دامنهی FineVision را به ویدیو، زبانهای بیشتر و گفتوگوهای طولانیتر گسترش دهد،
سیستمهای بازبینی انسانی را دقیقتر کند تا سوگیریها و مشکلات مجوزی به حداقل برسند،
و ابزارهای منبعباز بیشتری برای تحلیل و پاکسازی داده در اختیار جامعه قرار دهد.
FineVision ثابت کرد که مقیاس بزرگ زمانی ارزشمند است که با کیفیت و شفافیت همراه باشد.
این پروژه، راه را برای آیندهای بازتر و منصفانهتر در توسعهی مدلهای زبانی–تصویری هموار کرده است.

{kind=link}
بدون دیدگاه