
DINOv3 چیست؟ معرفی کامل مدل خودنظارتی متا (Meta AI)
در چند سال اخیر، نام DINOv3 بارها در دنیای هوش مصنوعی (Artificial Intelligence – AI) و بینایی کامپیوتر (Computer Vision) شنیده شده است. این مدل جدید که توسط شرکت متا (Meta) — همان شرکت مادر فیسبوک (Facebook) — معرفی شده، سومین نسل از خانواده مدلهای DINO است.
نام آن از عبارت Distillation with No Labels به معنی «تقطیر بدون نیاز به برچسب» گرفته شده است.
به زبان ساده، DINOv3 مدلی است که میتواند بدون داشتن دادههای برچسبخورده (labelled data)، از میلیونها تصویر خام یاد بگیرد و چیزهایی مثل شکلها، رنگها، و الگوها را خودش تشخیص دهد. این توانایی باعث شده DINOv3 در بسیاری از کاربردهای دنیای واقعی مانند پلاکخوان خودرو (OCR / License Plate Recognition)، تشخیص اشیاء (Object Detection)، طبقهبندی تصاویر (Image Classification) و حتی کاربردهای پزشکی بسیار مؤثر باشد.
مفهوم یادگیری خودنظارتی (Self-Supervised Learning)
برای درک بهتر DINOv3، باید بدانیم که یادگیری خودنظارتی (Self-Supervised Learning) چیست.
در یادگیری نظارتی معمولی (Supervised Learning)، مدل برای آموزش به دادههایی نیاز دارد که هرکدام برچسب (Label) دارند — مثلاً تصویری از گربه با برچسب “cat”. اما جمعآوری و برچسبگذاری میلیونها تصویر کاری زمانبر و پرهزینه است.
در مقابل، در یادگیری خودنظارتی، مدل خودش از دادهها الگو میسازد. یعنی بدون اینکه کسی به آن بگوید «این گربه است یا سگ»، خودش سعی میکند ویژگیها (Features) و روابط بین بخشهای تصویر (Patterns) را کشف کند.
DINOv3 از همین ایده استفاده میکند و با نگاه کردن به میلیونها تصویر بدون برچسب، یاد میگیرد که درک بصری قویای از دنیای تصاویر داشته باشد.
از DINO تا DINOv3؛ مسیر تکامل مدلهای متا
DINO (نسخه اول)
اولین نسخه DINO توسط محققان متا معرفی شد تا نشان دهند که میتوان یک مدل Vision Transformer (ViT) را بدون برچسب آموزش داد. این مدل از دو شبکه استفاده میکرد:
یک شبکه دانشآموز (Student Network) و یک شبکه معلم (Teacher Network).
مدل دانشآموز یاد میگرفت خروجی خود را به خروجی معلم نزدیک کند، بدون اینکه به برچسب نیاز داشته باشد.
DINOv2 (نسخه دوم)
در نسخه دوم، DINOv2، عملکرد مدل در درک جزئیات تصویر بسیار بهتر شد. DINOv2 میتوانست ویژگیهای بصری را با دقت بالاتری استخراج کند و در وظایفی مثل تقسیمبندی تصویر (Segmentation) و ردیابی اشیاء (Tracking) نتایج خوبی به دست آورد.
DINOv3 (نسخه سوم و پیشرفتهترین)
اما با DINOv3، متا پا را فراتر گذاشت. این مدل با میلیاردها تصویر آموزش دیده و در مقیاس بسیار بزرگ طراحی شده است.
DINOv3 قادر است بدون نیاز به دادههای برچسبدار، درک عمیقی از ساختار درونی تصاویر (Image Structure) پیدا کند.
یکی از نوآوریهای مهم DINOv3 استفاده از تکنیکی به نام Gram Anchoring است که از فروپاشی ویژگیها (Feature Collapse) جلوگیری میکند. این روش باعث میشود مدل بتواند هم ویژگیهای محلی (Local Features) و هم ویژگیهای کلی (Global Features) تصویر را بهخوبی یاد بگیرد.

فرآیند آموزش مدل DINOv3 در یک نگاه: از گردآوری دادههای خام و متعادل تا یادگیری خودنظارتی (SSL) در مقیاس بزرگ، لنگراندازی گرَم (Gram Anchoring) برای بهبود ویژگیهای محلی و جلوگیری از افت کیفیت ویژگی های متراکم در تمرین طولانی مدت، فاینتیونینگ با دادههای باکیفیت، و در نهایت تقطیر مدل (Model Distillation) برای پوشش اندازههای مختلف مدلها
ساختار مدل (Architecture) DINOv3
DINOv3 بر پایه Vision Transformer (ViT) طراحی شده است — همان مدلی که در دنیای بینایی کامپیوتر جایگزین شبکههای عصبی کانولوشنی (CNN) شده است.
این معماری مبتنی بر پچها (Patches) است: تصویر به قطعات کوچکی تقسیم میشود و مدل یاد میگیرد هر پچ را مانند یک توکن (Token) درک کند، درست مانند نحوهی کار مدلهای زبانی (مثل GPT).
همچنین نسخههایی از DINOv3 وجود دارند که بر پایه ConvNeXt Backbone ساخته شدهاند تا در دستگاههایی با منابع کمتر (مثل GPUهای ضعیفتر یا موبایل) هم قابل اجرا باشند.
آموزش مدل (Training) در مقیاس بزرگ
در فرآیند آموزش DINOv3، متا از ۱٫۷ میلیارد تصویر بدون برچسب استفاده کرده است.
مدل اصلی (Teacher) بیش از ۷ میلیارد پارامتر (Parameters) دارد و بر روی سیستمهای GPU بسیار قدرتمند آموزش داده شده است.
این مدل با ترکیب دو بخش آموزش دانشآموز و معلم (Student–Teacher Framework)، خروجی پایدار و دقیقی تولید میکند.
در عمل، این روش نوعی تقطیر دانش (Knowledge Distillation) محسوب میشود، جایی که مدل بزرگتر (معلم) دانش خود را به مدل کوچکتر (دانشآموز) منتقل میکند. همین فرایند باعث شده نام مدل نیز Distillation with No Labels باشد.
ویژگیها و قابلیتهای کلیدی DINOv3
- یادگیری بدون برچسب (Unlabeled Data Training)
– مدل بدون نیاز به دیتاستهای برچسبدار آموزش میبیند. - پشتیبانی از دادههای تصویری و ویدیویی (Image & Video Processing)
– برای وظایفی مثل ردیابی اشیاء (Object Tracking) و تشخیص الگو (Pattern Recognition) ایدهآل است. - مقیاسپذیری بالا (Scalability)
– میتواند از دادههای کوچک تا عظیم را مدیریت کند. - سازگاری با کاربردهای مختلف (Versatility)
– از پلاکخوان (OCR) تا پزشکی (Medical Imaging)، از وب (Web Applications) تا نرمافزارهای موبایل. - قابلیت یادگیری بدون نیاز به تنظیم دقیق (Zero-shot & Fine-tuning)
– در بسیاری از وظایف، حتی بدون آموزش مجدد، عملکرد چشمگیری دارد.
کاربردهای DINOv3 در دنیای واقعی
ابتدا به کاربردهای DINOv3 که داخل خود وبلاگ شرکت متا اشاره شده میپردازیم که نزدیک ترین لبه تکنولوژی جهان در عمل هستند و سپس تعدادی از کاربردهایش که توسط کاربران مختلف در سراسر جهان به آنها اشاره شده است را بررسی کردیم:


انکولوژی اوراکل Orakl Oncology با استفاده از DINO روی تصاویر ارگانوئیدها از قبل آموزش میدهد و یک ستون فقرات برای پیشبینی قدرتمند پاسخ بیمار به درمانهای سرطان ایجاد میکند.
آزمایشگاه پیشرانه جت JPL ناسا از DINO برای رباتهای اکتشافی مریخ استفاده میکند و امکان انجام چندین کار بینایی را با حداقل محاسبات فراهم میکند.
موسسه منابع جهانی WRI با استفاده از DINO ارتفاع تاج درختان را اندازهگیری میکند و به سازمانهای جامعه مدنی در سراسر جهان در نظارت بر احیای جنگلها کمک میکند.
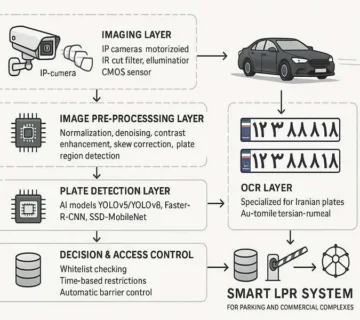
- پلاکخوان و OCR (Optical Character Recognition)
– خواندن اعداد و حروف از پلاک خودروها یا تصاویر اسناد. - تشخیص اشیاء (Object Detection)
– تشخیص خودرو، انسان، حیوانات و اجسام در تصویر یا ویدیو. - تقسیمبندی تصویر (Segmentation)
– تفکیک بخشهای مختلف تصویر مانند جاده، آسمان یا چهره. - طبقهبندی تصویر (Classification)
– دستهبندی خودکار تصاویر در گروههای مشخص. - کاربردهای پزشکی (Medical Applications)
– تشخیص الگوهای غیرعادی در عکسهای MRI یا X-ray. - وباپلیکیشنها و پروژههای AI آنلاین (Web & API Applications)
– استفاده از مدل در پروژههای پایتون (Python)، PyTorch، یا حتی اجرای مدل در Colab. - تحلیل ویدیو در زمان واقعی (Realtime Video Analysis)
– برای نظارت شهری، امنیت، ویدیوهای آموزشی و تحلیل رفتار.
مقایسه DINOv3 با YOLO و مدلهای مشابه
مدلهای YOLO (You Only Look Once) سالهاست در زمینهی تشخیص اشیاء (Object Detection) کاربرد دارند.
اما تفاوت مهم DINOv3 با YOLO این است که DINOv3 بدون برچسب یاد میگیرد، در حالی که YOLO نیاز به دادههای برچسبدار دارد.
همچنین DINOv3 بهدلیل استفاده از معماری Transformer، قادر است روابط پیچیده بین بخشهای تصویر را بهتر درک کند و در بسیاری از وظایف دقیقتر عمل کند.
به طور خلاصه:
| ویژگی | DINOv3 | YOLOv8 | DETR |
|---|---|---|---|
| نوع یادگیری | خودنظارتی (Self-Supervised) | نظارتی (Supervised) | نظارتی (Supervised) |
| نیاز به داده برچسبدار | ندارد ❌ | دارد ✅ | دارد ✅ |
| معماری | Vision Transformer (ViT) | CNN + CSPDarknet | Transformer + CNN |
| دقت درک ویژگیها | بسیار بالا ⭐⭐⭐⭐ | بالا ⭐⭐⭐ | بالا ⭐⭐⭐ |
| سرعت اجرا (Real-time) | نسبتاً پایینتر 🕐 | بسیار سریع ⚡ | متوسط ⚙️ |
| کاربرد اصلی | یادگیری ویژگیها، بینایی عمومی، OCR | تشخیص اشیاء و ردیابی در ویدیو | تشخیص و تقسیمبندی اشیاء |
| پشتیبانی از داده خام | بله ✅ | خیر ❌ | خیر ❌ |
| سازنده | Meta AI | Ultralytics | Facebook AI Research |
استفاده از DINOv3 در پایتون و PyTorch
محققان و برنامهنویسان میتوانند از مدل DINOv3 از طریق HuggingFace یا GitHub Repository رسمی متا استفاده کنند.
برای اجرای مدل در پایتون، کافی است از کتابخانه PyTorch استفاده شود.
بهعنوان مثال، در Google Colab میتوان با چند خط کد مدل را بارگیری کرد و از آن برای استخراج ویژگیها (Feature Embedding) استفاده نمود.
این مدل دارای مجوز بازمتن (Open License) است و در HuggingFace Hub نسخههای کمحجمتر و Quantized نیز موجود است تا بتوان روی GPUهای معمولی هم اجرا کرد.
چرا DINOv3 نقطه عطفی در یادگیری ماشین است؟
DINOv3 نه فقط یک مدل بینایی، بلکه یک پایهگذار نسل جدید هوش مصنوعی خودآموز (Self-Evolving AI) محسوب میشود.
این مدل نشان داد که سیستمهای هوش مصنوعی میتوانند مانند مغز انسان (Brain-inspired Learning)، با دیدن دادههای خام، الگوها را کشف و معنا را درک کنند.
در آینده، DINOv3 میتواند در سیستمهای پزشکی، امنیتی، فضایی (NASA Projects) و حتی برنامههای وب هوشمند (Smart Web Applications) نقشی محوری داشته باشد.
جمعبندی
مدل DINOv3 حاصل سالها تحقیق و توسعه در شرکت Meta (فیسبوک سابق) است.
این مدل با تکیه بر روش یادگیری خودنظارتی (Self-Supervised Learning)، بدون نیاز به برچسب داده، به یکی از قویترین مدلهای بینایی در جهان تبدیل شده است.
ترکیب فناوریهای پیشرفتهای مانند Transformer Architecture، Gram Anchoring، و Knowledge Distillation باعث شده این مدل در کاربردهای پردازش تصویر (Image Processing)، تشخیص الگو (Pattern Recognition)، و بینایی ماشین (Computer Vision) بهصورت Real-time و با دقت بالا عمل کند.
بهبیان سادهتر، DINOv3 همانند مغزی است که خودش میبیند، خودش یاد میگیرد و خودش تصمیم میگیرد — بدون اینکه کسی به آن بگوید «چه چیزی را باید ببیند».

){kind=link}
بدون دیدگاه