
BDH (جوجه اژدها)؛ معماری پلی نوین میان ترنسفورمر و مدلهای مغزی
معماری هوش مصنوعی معمولاً دو قطب دارد: معماری ترنسفورمر و مدل زیست مغزی. هر کدام جهان خودشان را دارند. اما اخیراً مقالهای منتشر شده با عنوان «جوجه اژدها: حلقه گمشده بین ترنسفورمر و مدلهای زیست مغزی» که ادعا میکند میتواند «پل» بین این دو جهان بسازد. در این مطلب میخواهیم ببینیم جوجه اژدها چیست، چگونه عمل میکند، چرا مهم است و چه تأثیری ممکن است بر آیندهی هوش مصنوعی داشته باشد.
مقدمه: دو جهان متفاوت
پیش از اینکه وارد شرح معماری جوجه اژدها بشویم، باید با دو دنیا آشنا شویم:
معماری ترنسفورمر
مدل زیست مغزی
و بفهمیم چه چیزی آنها را از هم جدا کرده است — و چرا ساختن یک «پل» بینشان بزرگ است.
معماری ترنسفورمر چیست؟
معماری ترنسفورمر (Transformer) به عنوان یکی از پایههای اصلی مدلهای زبانی بزرگ شناخته میشود.
در این معماری:
ورودی (مثلاً یک جمله) ابتدا به بردارهای عددی تبدیل میشود (embedding).
سپس هر توکن (کلمه یا نماد) میتواند به تمام توکنهای دیگر «توجه» کند (attention).
عملیات attention معمولاً به شکل ریاضی با بردارهای Query، Key و Value انجام میشود:
در کنار attention، بخشهایی به نام feedforward layers وجود دارند که تغییرات خطی و غیرخطی روی بردارها انجام میدهند.
یادگیری در این معماری عمدتاً از طریق گرادیانها و الگوریتمهایی مثل Backpropagation انجام میشود.
ارتباط بین توکنها کاملاً سراسری (global) است: هر توکن میتواند مستقیماً بر هر توکن دیگر تأثیر بگذارد.
مزیت بزرگ ترنسفورمر این است که امکان یادگیری روابط پیچیده بین اجزای یک توالی را فراهم میکند، اما مشکل اصلی آن این است که ساختارش تفاوت زیادی دارد باآنچه در مغز زیستی رخ میدهد.
مدل زیست مغزی چیست؟
مدل زیست مغزی (biological brain model) تلاش میکند عملکرد مغز واقعی را در سطح نورونها و سیناپسها شبیهسازی کند، نه فقط به عنوان معادلات خطی یا برداری، بلکه به صورت شبکهای پویا.
در این مدل:
نورون واحد پردازش است؛ نورون سیگنالهای ورودی را جمع کرده و اگر به آستانهای برسد، یک پالس (spike) ارسال میکند.
بین نورونها، سیناپس برقرار است؛ وزن سیناپس تعیین میکند چقدر سیگنال منتقل شود.
پلاستیسیته سیناپسی وجود دارد: یعنی وزن سیناپسها میتواند تغییر کند با توجه به تجربه و فعالیت نورونها.
یکی از مشهورترین قوانین برای بهروزرسانی وزن سیناپس، قانون Hebb است:
اگر نورونها همزمان فعال شوند، اتصال بینشان قویتر میشود.
این یادگیری غالباً محلی (local learning) است؛ یعنی هر نورون یا سیناپس فقط به وضعیت همسایگان خودش نگاه میکند، نه تمام شبکه به صورت متمرکز.
فعالیت نورونها میتواند در زمان پیوسته و دینامیکی دنبال شود (نه فقط گسسته).
شبکههای زیستی معمولاً ماژولار هستند و اتصالها اغلب سنگیندم (heavy-tailed degree distribution) دارند؛ یعنی تعداد کمی نورون بسیار پرتصل دارد و بسیاری نورونها اتصال کمی دارند.
این مدل زیست مغزی به ما نزدیکتر است به آنچه در مغز واقعی اتفاق میافتد، اما مشکل بزرگش این است که هنوز توانایی رقابت در وظایف پیچیده زبان یا ترجمه را ندارد.
BDH چیست؟
نام کامل این مدل BDH (Dragon Hatchling) است. مقالهای بهتازگی منتشر شده با عنوان “The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain” که میگوید BDH میتواند یک پل بین معماری ترنسفورمر و مدل زیست مغزی باشد.
در BDH:
شرکتکنندگان مدل (نورونها) به صورت locally هستند؛ یعنی نورونها با نورونهای نزدیک تعامل دارند.
وزنهای سیناپسی روی لبههای یک گراف قرار دارند. وضعیت لبهها (اتصالات) در حین استنتاج تغییر میکند.
یادگیری در زمان استنتاج از طریق قانون Hebb انجام میشود — یعنی اگر دو نورون همزمان فعال شوند، وزن سیناپس بینشان تقویت میشود.
مدل BDH به شکلی طراحی شده است که تعبیرپذیری داشته باشد: وضعیت سیناپسها، فعالسازی نورونها، مفاهیم درون شبکه — همه قابل مشاهدهاند.
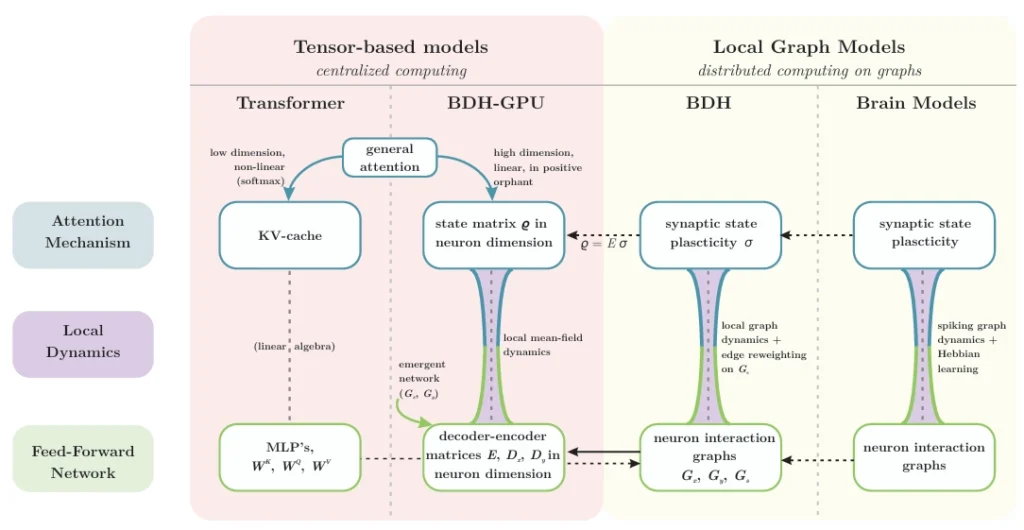
نمای کلی از معماریها و روابط آنها: دینامیک استنتاج BDH و BDH-GPU بهعنوان پل طبیعی بین ترنسفورمر و مدلهای مغز عمل میکند. دو مکانیزم اصلی استنتاج در یک معماری استدلال، یعنی توجه و شبکه پیشخور، در سطح کلان از طریق عملگرهای تنسوری برای ترنسفورمر و در سطح خرد تعاملات نورونی از طریق دینامیکهای گراف محلی برای مدلهای مغز تعریف میشوند. معماری جدید BDH-GPU بهطور طبیعی هم در سطح بردارها و هم در سطح دینامیک ذرات نورونها و سیناپسها تعریف میشود و بهعنوان پل بین این دو رویکرد عمل میکند.
یک نسخه سازگار با GPU از این مدل ارائه شده است با نام BDH -GPU که مسئلهی اجرا در سختافزار معمولی را حل میکند.
BDH تلاش میکند رفتار attention را به صورت محلی در سطح نورونها بازسازی کند؛ یعنی آنچه در ترنسفورمر با ضرب ماتریسی اتفاق میافتد، در BDH به صورت تعاملهای محلی لبهای بازنمایی میشود.
در آزمایشها، BDH عملکردی تقریباً مشابه GPT-2 نشان داده است.
شبکه تعامل نورونها در BDH دارای ساختار ماژولار است و توزیع درجه سنگیندم دارد (یعنی برخی نورونها خیلی متصلاند).
به عبارت ساده جوجه اژدها مدلی است که سعی میکند بهترینهای هر دو جهان را داشته باشد. قدرت ترنسفورمر و شباهت به مغز زیستی.

نمایش سیستم فیزیکی BDH به عنوان یک مدل اسباب بازی گراف فیزیکی در یک سیستم 5 ذرهای که با رابط های الاستیک به یکدیگر متصل شدهاند. دینامیک فعال ساز x,y روی گره ها که بیشتر شبیه پالس هستند و به طور منظم و در مقیاس زمانی سریع ظاهر و ناپدید میشوند. هنگامی که یک رابط الاستیک بین ذرات i و j به ترتیب در حالت های x و y جابجا شود کششی روی این رابط ظاهر میشود که باعث جابجایی آن (i,j)σ میشود که با گذشت زمان شل میشود.
جوجه اژدها (BDH) چگونه کار میکند؟
در ادامه سعی میکنم روند کار BDH را به شکلی ساده توضیح دهم، طوری که حتی کسی که آشنایی عمیق با هوش مصنوعی ندارد، بتواند بفهمد.
گراف نورونها و لبهها جوجه اژدها
تصور کن یک شبکه از نورونها داریم که با لِبهها (اتصالات) به هم وصلاند. هر لبه یک وزن دارد — مانند یک سیناپس. در ابتدای کار، وزنها تنظیم شدهاند (پارامترهای مدل).
وقتی ورودی (مثل یک کلمه) وارد مدل میشود، نورونها فعال میشوند و سیگنالها از طریق لبهها پخش میشوند. این فرآیند استنتاج (inference) است.
بهروزرسانی وزن سیناپس در زمان استنتاج
در حالت عادی، مدلها ابتدا آموزش میبینند، سپس ثابت میمانند و هنگام استنتاج تغییری نمیکنند.
اما در BDH، وضعیت لبهها (وزن سیناپسها) در زمان استنتاج تغییر میکند بر اساس قانون Hebb. اگر نورون i و نورون j همزمان فعال شوند، وزن سیناپس بین i و j کمی تقویت میشود. این پدیده «پلاستیسیته سیناپسی» نامیده میشود.
این ویژگی باعث میشود BDH حافظهی پویایی داشته باشد، و بتواند به مفاهیم در طول پردازش پاسخ دهد.
بازسازی مکانیزم attention به صورت محلی
یکی از نوآورانهترین بخشها این است که BDH نشان میدهد مکانیسم attention در ترنسفورمر را میتوان به قواعد محلی لبهای تبدیل کرد. یعنی به جای آنکه هر توکن به همهی توکنها نگاه کند، نورونها به نورونهای نزدیکشان نگاه میکنند و وزنهای لبه را طوری بهروزرسانی میکنند که در کل شبکه اثر مشابه attention ایجاد شود. این همان «پل بین دو جهان» است.
نسخه GPU و بهینهسازیهای BDH
برای اینکه BDH قابل استفاده در عمل باشد، نسخهای به نام BDH -GPU عرضه شده است. در این نسخه:
آرایش مدل طوری است که بتواند بر روی GPU اجرا شود.
از بلوکهایی به نام ReLU-lowrank استفاده میشود تا محاسبات بهینهتر باشند.
فعالسازی (activation) نورونها مثبت و پراکنده (sparse positive activation) است: فقط بعضی مؤلفهها فعالند، نه تمامیشان.
رفتار مدل در مقیاسهای بزرگ مشابه رفتار ترنسفورمرها است (یعنی وقتی پارامترها افزایش مییابند، کاهش خطا مطابق الگوی مشابهی رخ میدهد).
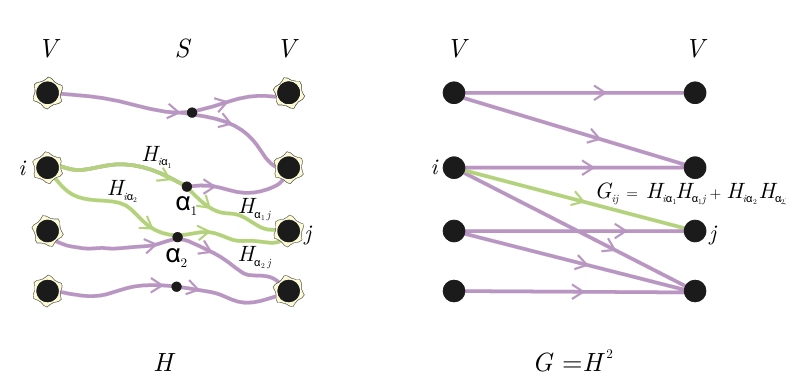
ارتباط نورون-نورون با استفاده از گرافهای G ∈ ξ²(n,m): تناظر بین گراف H با m یال (چپ) و گراف برهمکنش نورون-نورون G = H² (راست). این رویکرد امکان بیان انتشار سیگنال خطی را روی دسته وسیعی از گرافهای ξ²(n,m) با استفاده از دو مرحله دینامیک خطی روی یک مدار پراکنده H فراهم میکند، یعنی Gz = H²z برای z ∈ (R+)n
اهمیت جوجه اژدها و کاربردها
چرا این مدل جالب و مهم است؟ در زیر چند نکتهی کلیدی:
- پل بین دو دنیای متفاوت
معماری ترنسفورمر و مدل زیست مغزی تا امروز یکدیگر را خیلی کم درک کردهاند. جوجه اژدها به ما یک پل میدهد، یعنی میگوید که میتوان مدلی داشت که هم شبیه مغز باشد و هم عملکردی مانند ترنسفورمر داشته باشد. - تعبیرپذیری (Interpretability)
برخلاف مدلهای سیاه مثل بسیاری از مدلهای بزرگ زبانی، در BDH وضعیت نورونها و سیناپسها قابل مشاهده و تفسیر است. مفهوم monosemantic synapses یکی از نتایج جذاب همین تفسیرپذیری است. - پلاستیسیته و آداپتیویته (توان تطبیق)
چون وزنها در زمان استنتاج تغییر میکنند، BDH میتواند به صورت پویا به دادههای جدید واکنش نشان دهد— چیزی که در مدلهای کلاسیک معمول نیست. - وجود ساختار زیستی در شبکه
شبکه نورونها در BDH دارای ماژولار بودن و توزیع سنگیندم است؛ ویژگیهایی که در شبکههای واقعی مغزی دیده شدهاند. - کارایی رقابتی
در مقیاس بین ۱۰ میلیون تا ۱ میلیارد پارامتر، BDH توانسته عملکردی مشابه GPT-2 نشان دهد، یعنی ثابت کرده که این ایده فقط تئوری نیست بلکه قابل اجراست.
چالشها و محدودیتهای BDH
با وجود جذاب بودن مدل، چند نکته مشکلساز وجود دارد:
عملکرد BDH در مقیاسهای بسیار بزرگ (چند دهها میلیارد پارامتر) هنوز اثبات نشده است.
پیچیدگی محاسبات و منابع سختافزاری ممکن است مانع اجرای واقعی آن در صنایع شود.
ادعای زیستپسند بودن باید با دادههای بیولوژیکی تأیید شود؛ ممکن است مغز واقعی متفاوت عمل کند.
تعمیم به حوزههای غیر زبانی (مانند بینایی، کنترل، تصاویر) هنوز بررسی نشده است.
پایداری یادگیری محلی، همگرایی قوانین دینامیکی، جلوگیری از نوسان — این موارد در مدلهای دینامیکی نیاز به بررسی عمیق دارند.
چگونه BDH میتواند در آینده تأثیر بگذارد؟
BDH باعث هدایت تحقیقات بین علوم عصبی و یادگیری ماشین به سمت مدلهایی که هم کارا هستند هم قابل فهم.
سازگاری بهتر مدلهای زبانی با انسان، چون مفاهیم درون شبکه تفسیرپذیرند.
فرصت برای ترکیب ماژولها، “جراحی مدل” (model surgery) و ادغام بخشهای مختلف از مدلهای متفاوت.
امکان ایجاد چارچوبی مانند «محدودیت ترمودینامیکی (Thermodynamic Limit)» برای رفتار مدل در مقیاس بزرگ.
کمک به طراحی سیستمهای ایمنتر و قابل پیشبینیتر در آیندهی هوش مصنوعی.
جمعبندی و نتیجهگیری
در این مطلب فهمیدیم:
معماری ترنسفورمر چگونه کار میکند، ارتباط سراسریاش با توکنها چیست، و ضعفهایش کجاست.
مدل زیست مغزی چه مفهومی دارد، چگونه نورون و سیناپس را شبیهسازی میکند و محدودیتهایش کدام است.
جوجه اژدها (BDH) چیست: مدلی که میکوشد بین این دو جهان یک پل واقعی بسازد، یعنی قدرت ترنسفورمر + ساختار زیستی را باهم داشته باشد.
مزایا، چالشها و چشماندازهای آیندهی این مدل را مرور کردیم.

{kind=link}
بدون دیدگاه