
یادگیری عاملها از طریق تجربهی اولیه: راهی نوین برای هوش مصنوعی خودآموز
یادگیری عاملها از طریق تجربهی اولیه؛ انقلابی در آموزش هوش مصنوعی بدون پاداش
در چند سال اخیر، واژهی عامل زبانی (Language Agent) تبدیل به یکی از داغترین مفاهیم در هوش مصنوعی شده است.تجربهی اولیه این عاملها، همان سیستمهایی هستند که میتوانند با زبان طبیعی کار کنند — مثلاً در وب جستوجو کنند، فرم پر کنند، ایمیل بنویسند، یا حتی ابزارهای مختلف را ترکیب کنند تا به هدفی برسند.
اما سؤال بزرگ این است:
چگونه میتوانیم این عاملها را طوری آموزش دهیم که خودشان از تجربهی خود یاد بگیرند؟
پژوهش تازهای از Meta Superintelligence Labs و دانشگاه ایالتی اوهایو (Ohio State University) پاسخی هوشمندانه برای این سؤال ارائه میدهد. این مقاله که با عنوان Agent Learning via Early Experience منتشر شده، یک چارچوب نو به نام تجربهی اولیه (Early Experience) معرفی میکند — روشی که میتواند شکاف میان «یادگیری تقلیدی» و «یادگیری تقویتی» را پر کند.
مسئله ی تجربهی اولیه از کجا شروع شد؟
تا امروز بیشتر عاملهای هوشمند با دادههای انسانی یا پاداشهای صریح آموزش میدیدند. اما هر دو مسیر چالشهای خاص خود را دارند:
1. یادگیری تقلیدی (Supervised / Imitation Learning)
در این روش، عامل فقط رفتار متخصص را تقلید میکند.
مثلاً اگر هدف خرید کالا در یک سایت است، مدل فقط نمونههایی را میبیند که انسان قبلاً درست انجام داده.
اما هرگز تجربه نمیکند که اگر مسیر اشتباهی را برود چه میشود.
در نتیجه، این عاملها نمیتوانند از اشتباهات خود یاد بگیرند، در موقعیتهای جدید ضعیف عمل میکنند، و رشدشان محدود به دادههای انسانی است.
مقاله مرتبط با این مقاله را با عنوان یادگیری تقویتی عاملمحور برای مدلهای زبان بزرگ گام بعدی هوش مصنوعی خودمختار مطالعه کنید.
2. یادگیری تقویتی (Reinforcement Learning)
اینجا عامل در محیط آزمایش میکند و برای هر عمل خوب پاداش میگیرد.
مثلاً در بازی Go، سیستم AlphaGo با میلیونها بار بازی، یاد گرفت چطور برنده شود.مقاله AlphaGo را مظالعه کنید.
اما مشکل زمانی پیش میآید که محیط، پاداش مشخصی ندارد.
در وب، مثلاً عامل فرم رزرو هتل را پر میکند، ولی هیچ نشانهای از درست یا غلط بودن ندارد. یا باید هزاران مرحله را طی کند تا در انتها بفهمد موفق بوده یا نه. این فرایند بسیار کند و پرهزینه است.
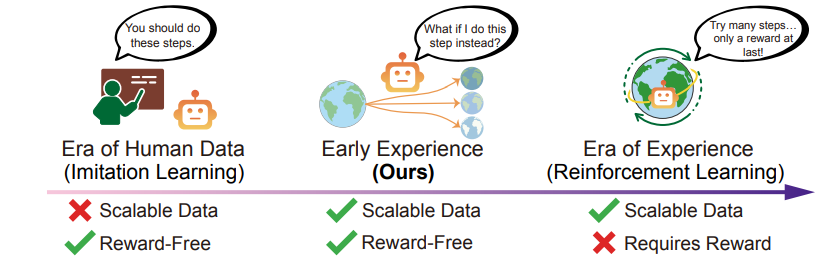
تجربهی اولیه: راه سوم میان تقلید و پاداش
محققان مقاله میگویند لازم نیست همیشه پاداش صریح وجود داشته باشد تا عامل یاد بگیرد.
بلکه میتوان خودِ تجربههای اولیهی عامل را به منبع یادگیری تبدیل کرد.
در این روش، عامل علاوه بر دیدن مثالهای انسانی، خودش هم در محیط عمل میکند، نتایج را مشاهده میکند، و از همان نتایج یاد میگیرد.
این همان چیزی است که انسانها هم انجام میدهند: اشتباه میکنند، بازخورد میبینند، و تجربه میسازند.
بیایید تصور کنیم عاملی را که وظیفه دارد بلیت پرواز رزرو کند.
او یاد میگیرد:
اگر تاریخ اشتباه وارد کند، سایت پیام خطا میدهد.
اگر مقصد را جا بگذارد، فرم ناقص میماند.
اگر دکمهی اشتباهی بزند، به صفحهی دیگری میرود.
حتی بدون پاداش مستقیم، همین پیامها و نتایج تبدیل به بازخورد میشوند.
عامل از آنها میآموزد که چه کارهایی درست یا نادرست است.
دو ستون اصلی در تجربهی اولیه
چارچوب تجربهی اولیه بر دو مفهوم کلیدی بنا شده است:
🔹 ۱. مدلسازی ضمنی جهان (Implicit World Modeling)
در این روش، عامل یاد میگیرد که جهان اطرافش چطور واکنش نشان میدهد.
یعنی از روی وضعیت فعلی و عملی که انجام میدهد، پیشبینی میکند که وضعیت بعدی چه خواهد بود.بهطور ساده، عامل میپرسد:”اگر این کار را انجام دهم، چه می شود؟”
برای مثال، اگر در سایت خرید، عامل روی گزینهی اشتباه کلیک کند و خطا ببیند، یاد میگیرد که در آینده آن گزینه اشتباه است.
در نتیجه، ذهنی از «رفتار محیط» برای خودش میسازد، بدون اینکه نیاز به شبیهسازی یا پاداش داشته باشد.این رویکرد باعث میشود عامل انعطافپذیرتر، پیشبینتر و مقاومتر شود — حتی وقتی محیط تغییر میکند.
🔹 ۲. خودبازتابی (Self-Reflection)
در این روش، عامل بعد از انجام عمل، به رفتار خودش فکر میکند.او با مقایسهی عمل خودش با عمل صحیح (یا دادهی انسانی) سعی میکند بفهمد چرا انتخابش کمتر بهینه بوده.برای این کار، عامل از قدرت زبان استفاده میکند و استدلال خود را بهصورت نوشتاری توضیح میدهد.
مثلاً:”در این وضعیت ، گزینه ی قرمز جذاب بود اما از بودجه ی کاربر بیشتر بود.انتخاب آبی بهتر است چون با شرایط هماهنگ است.”
به این ترتیب، عامل فقط تقلید نمیکند؛ بلکه منطق تصمیمگیری را یاد میگیرد.
این باعث میشود بتواند در موقعیتهای جدید هم تصمیمهای درستی بگیرد — حتی بدون دیدن نمونهی مشابه در دادهی آموزشی.

نتایج آزمایشها
تیم پژوهشی این دو روش را در هشت محیط متفاوت آزمایش کرد؛ از جمله:
شبیهسازهای خانگی (ALFWorld)
محیطهای علمی (ScienceWorld)
برنامهریزی سفر (TravelPlanner)
خرید در وب (WebShop)
پرسشوپاسخ چندمرحلهای (SearchQA)
استفاده از APIها (BFCLv3, TauBench)
و محیط وب پیچیده (WebArena)
در تمام این محیطها، عاملهایی که با تجربهی اولیه آموزش دیده بودند:
عملکرد بهتری نسبت به تقلید خالص داشتند،
در محیطهای جدید مقاومتر بودند،
و حتی با دادههای انسانی کمتر، به نتایج مشابه یا بهتر رسیدند.
در برخی محیطها مثل WebShop و TravelPlanner، نرخ موفقیت بیش از ۱۵٪ افزایش یافت. این یعنی عاملها یاد گرفتند از تجربههای خودشان «هوشمندانهتر» استفاده کنند.
گامی بهسوی یادگیری تقویتی بهتر
پژوهشگران سپس مرحلهی یادگیری تقویتی را روی همین مدلها اجرا کردند.
نتیجه جالب بود:
عاملهایی که ابتدا با تجربهی اولیه آموزش دیده بودند، در مرحلهی یادگیری با پاداشها سریعتر رشد کردند و به نتایج بالاتری رسیدند.
این یعنی تجربهی اولیه، پایهای محکم برای یادگیری تقویتی آینده است.
مثل دانشآموزی که قبل از آزمون نهایی، با تمرینهای آزمایشی و اشتباهاتش بهتر آماده میشود.
مزیتهای کلیدی تجربهی اولیه
| ویژگی | توضیح |
|---|---|
| یادگیری بدون پاداش | عامل از بازخوردهای طبیعی محیط یاد میگیرد، حتی بدون پاداش صریح. |
| مقیاسپذیری بالا | نیازی به دادههای انسانی زیاد یا گرانقیمت نیست. |
| یادگیری از خطا | عامل میتواند از اشتباهات خود آموزش ببیند و بهبود یابد. |
| قابلیت تعمیم | عملکرد بهتر در وظایف جدید و محیطهای ناشناخته. |
| پایهسازی برای RL | آمادهسازی عالی برای مرحلههای یادگیری تقویتی آینده. |
آیندهی عاملهای خودآموز
چارچوب تجربهی اولیه، پلی میان دو عصر است:
عصر دادههای انسانی (Imitation Era)
عصر تجربه و خودیادگیری (Experience Era)
در آینده، عاملهایی که با این روش آموزش میبینند، میتوانند:
خودشان بهصورت پیوسته یاد بگیرند؛
از خطاهای گذشته درس بگیرند؛
و در محیطهای واقعی بدون نظارت انسانی رشد کنند.
به این ترتیب، یادگیری ماشینی از تقلید صرف به سمت یادگیری تجربی هوشمندانه حرکت میکند — درست مثل انسانها.
سخن پایانی
مقالهی «Agent Learning via Early Experience» تنها دربارهی یک روش جدید آموزشی نیست؛ بلکه چشماندازی از آیندهی هوش مصنوعی است.
جهانی که در آن، عاملهای دیجیتال دیگر به دادههای انسانی وابسته نیستند؛
بلکه با تجربه، آزمایش، و بازتاب خود، به رشد و بلوغ میرسند.
بهزودی، «یادگیری از تجربه» نه فقط برای انسانها، بلکه برای هوش مصنوعی هم یک مسیر طبیعی خواهد بود — و این یعنی شروع واقعی عصر تجربه.

{kind=link}
بدون دیدگاه