
یادگیری تقویتی عاملمحور برای مدلهای زبان بزرگ (Agentic RL - Reinforcement Learning for LLMs): گام بعدی هوش مصنوعی خودمختار
در سالهای اخیر، هوش مصنوعی (Artificial Intelligence) وارد مرحلهای تازه شده است؛ مرحلهای که در آن مدلهای زبان بزرگ یا همان LLMs (Large Language Models) دیگر تنها پاسخدهنده به پرسشها نیستند، بلکه میتوانند بهصورت عاملمحور (Agentic) تصمیم بگیرند، عمل کنند و یاد بگیرند.
یکی از مفاهیم نوظهور که این تحول را ممکن کرده، یادگیری تقویتی عاملمحور (Agentic Reinforcement Learning – RL) است. این رویکرد در واقع ترکیبی از یادگیری تقویتی (Reinforcement Learning) و مدلهای زبانی (Language Models) است که به مدل اجازه میدهد رفتار خود را بر اساس بازخورد محیط بهینه کند.
در این مقاله به زبان ساده توضیح میدهیم Agentic RL چیست، چرا برای آیندهی هوش مصنوعی حیاتی است، چگونه عمل میکند و در چه حوزههایی به کار گرفته میشود.
Agentic RL چیست؟
یادگیری تقویتی عاملمحور (Agentic RL- Reinforcement Learning) نوعی روش یادگیری ماشین (Machine Learning) است که در آن یک عامل (Agent) بر اساس تعامل با محیط خود تصمیم میگیرد تا به هدفی خاص برسد.
عامل از طریق تجربه و پاداش (Reward) یاد میگیرد چه اقداماتی (Actions) سودمند هستند و کدامها نه.
در مدلهای زبانی بزرگ (LLMs)، این مفهوم به شکل تازهای ظاهر شده است. به جای آنکه مدل تنها متن تولید کند، اکنون میتواند:
برنامهریزی (Planning) کند،
ابزارها (Tools) را به کار بگیرد،
از حافظه (Memory) استفاده کند،
و حتی رفتار خود را بهبود دهد (Self-Improvement).
این همان چیزی است که به آن عامل LLM یا LLM Agent گفته میشود؛ مدلی که میتواند با محیط ارتباط بگیرد، داده جمع کند، و تصمیمهای هوشمندانه بگیرد.
تفاوت Agentic RL با یادگیری تقویتی سنتی
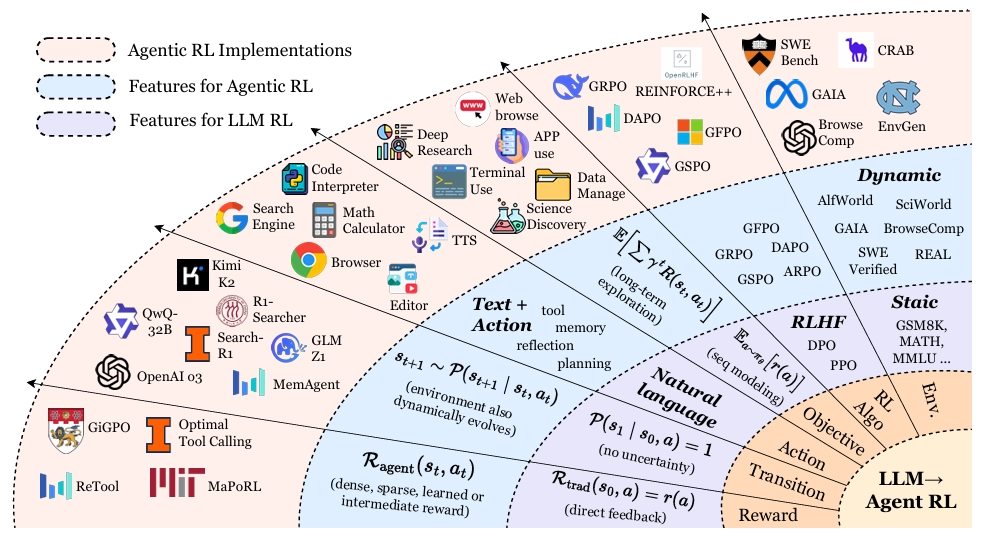
در یادگیری تقویتی کلاسیک، عامل معمولاً در محیطهایی با قوانین مشخص و پاداشهای واضح کار میکند، مثل بازیها یا شبیهسازها.
اما در Agentic RL، محیط بسیار پیچیدهتر است، چون دادههای زبانی، تعامل انسانی و عدم قطعیت (Uncertainty) در تصمیمگیری وجود دارد.
LLM RL سنتی (PBRFT):
- در این رویکرد، LLMها عمدتاً به عنوان مولدهای دنباله شرطی ایستا در نظر گرفته میشوند که برای تولید خروجیهای تکگامی بهینه شدهاند (مانند همسوسازی با ترجیحات انسانی).
- این فرآیند به طور رسمی به عنوان فرآیند تصمیمگیری مارکوف (MDP) تکمرحلهای فاسد (degenerate single-step MDPs) مدلسازی میشود.
- افق وظیفه (T): یکسان است (T=1)، یعنی اپیزود بلافاصله پس از تولید یک پاسخ به پایان میرسد.
- پاداش (Reward): یک پاداش عددی واحد (scalar) بر اساس عمل (r(a)) وجود دارد و بازخورد میانی (intermediate feedback) ارائه نمیشود.
- فضای عمل (Action Space): محدود به دنبالههای متنی خالص است.
یادگیری تقویتی عاملمحور (Agentic RL):
- در این پارادایم، LLMها به عنوان عاملهای خودران تصمیمگیرنده در نظر گرفته میشوند که در جهانهای پیچیده و پویا جای گرفتهاند.
- این فرآیند به عنوان فرآیند تصمیمگیری مارکوف با قابلیت مشاهده جزئی (POMDP) مدلسازی میشود که دارای قابلیت مشاهده جزئی و گسترش زمانی (multi-step, T>1) است.
- قابلیتها: RL، این مدلها را به قابلیتهای عاملی خودران، مانند برنامهریزی، استدلال، استفاده از ابزار، حفظ حافظه، و خودبازتابی مجهز میکند.
- فضای عمل: شامل دو جزء مجزا است: متن آزاد (Atext) و اعمال ساختاریافته غیرزبانی (Aaction). اعمال ساختاریافته میتوانند ابزارهای خارجی را فراخوانی کنند یا وضعیت محیط را تغییر دهند.
- پاداش: تابعی پاداش مرحلهای (Step-wise R(st, at)) استفاده میشود که ترکیبی از پاداشهای وظیفه پراکنده (sparse) و پاداشهای فرعی متراکم (dense sub-rewards) است.
- هدف یادگیری: حداکثر کردن پاداش تخفیف داده شده (discounted reward) در طول افق زمانی است (Jagent(θ)).
| ویژگی | RL سنتی | Agentic RL |
|---|---|---|
| نوع محیط | مشخص و ایستا | پویا و زبانی |
| نوع عامل | ساده و واکنشی | خودمختار و تعاملی |
| دادهها | عددی یا تصویری | متنی و چندوجهی |
| هدف | رسیدن به پاداش ثابت | یادگیری تصمیمگیری تطبیقی |
Agentic RL در واقع نسل بعدی RL است که با مدلهای زبانی ترکیب میشود تا به عاملهای هوشمند انسانینما (Human-like Agents) تبدیل شود.
ساختار مفهومی: MDP و POMDP
در مقالهی اصلی، نویسندگان برای توضیح این رویکرد از دو مفهوم ریاضی مهم استفاده کردهاند:
MDP (Markov Decision Process – فرایند تصمیمگیری مارکوفی):
در این مدل، عامل میداند در چه وضعیتی قرار دارد و با انتخاب عمل مناسب، به حالت بعدی میرود و پاداش دریافت میکند.POMDP (Partially Observable MDP – فرایند تصمیمگیری مارکوفی با مشاهده ناقص):
در دنیای واقعی، عامل همیشه نمیداند دقیقاً در چه وضعیتی است. بنابراین باید بر اساس تجربه قبلی و حافظه تصمیم بگیرد.
Agentic RL ترکیبی از این دو دیدگاه است؛ عامل بر اساس دانش محدود و محیط متغیر تصمیم میگیرد، مثل یک انسان.
قابلیتهای اصلی در Agentic RL
خلاصهای از شش جنبه کلی که در آن یادگیری تقویتی به مدلهای زبانی عاملمحور قدرت میبخشد. توجه داشته باشید که روشهای نماینده ذکر شده در اینجا کامل نیستند؛ برای مطالعه کامل به متن اصلی مقاله مراجعه کنید.
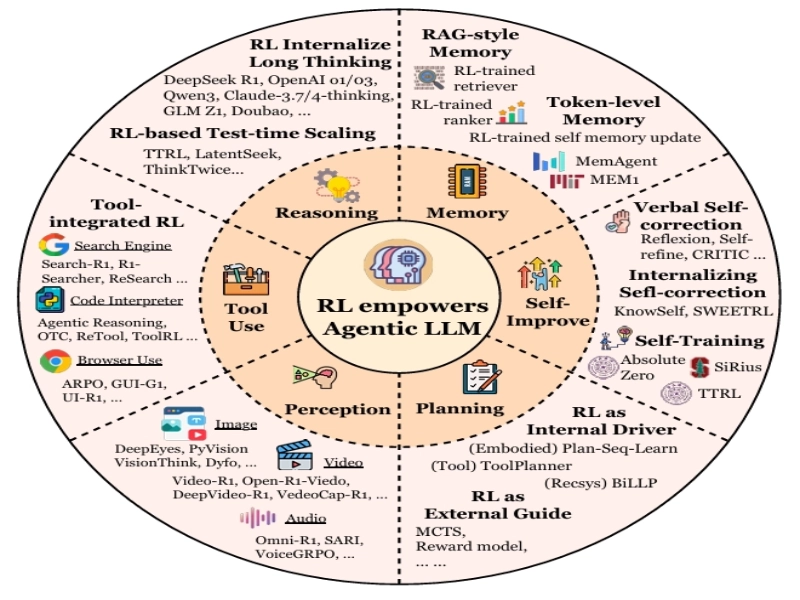
1. برنامهریزی (Planning)
عامل باید بتواند هدف را شناسایی کرده و مراحل رسیدن به آن را طراحی کند.
در LLM-RL، این کار معمولاً با الگوریتمهایی انجام میشود که توالی منطقی از اقدامات را میسازند (Plan–Execute–Reflect Loop).
RL برای پالایش استراتژیهای برنامهریزی عامل با یادگیری از بازخورد محیطی به کار میرود. این میتواند به صورت راهنمای خارجی برای الگوریتمهای جستجو (مانند MCTS) یا به عنوان راننده داخلی برای پالایش مستقیم سیاست برنامهریزی LLM باشد.
2. استدلال (Reasoning)
این بخش به مدل توانایی تفکر شبهمنطقی میدهد.
RL برای آموزش قابلیتهای استدلال آهسته (Slow Reasoning) و ساختاریافته (مانند Chain-of-Thought) به کار میرود، که شامل ساختار واضح برای جستجو و برنامهریزی، و رفتارهای مکرر تأیید و بررسی است.
3. استفاده از ابزار (Tool Use)
مثلاً ChatGPT یا Claude وقتی از مرورگر یا کد اینترپرتر استفاده میکنند، در واقع از قابلیت Tool Use بهره میبرند.
RL مدلها را قادر میسازد تا به طور خودکار تصمیم بگیرند که چه زمانی، چگونه و کدام ابزارها را برای بهینهسازی عملکرد نهایی استفاده کنند، و از تقلید الگوهای ایستا فراتر میرود. این شامل استدلال یکپارچه با ابزار (TIR) در حلقههای شناختی است.
4. حافظه (Memory)
این حافظه ممکن است بلندمدت (Long-term) یا کوتاهمدت (Short-term) باشد.
RL سیستمهای حافظه را از ذخیرهسازهای داده منفعل به زیرسیستمهای پویای کنترلشده تبدیل میکند که تصمیم میگیرند چه چیزی ذخیره، بازیابی یا فراموش شود. این شامل مدیریت حافظه RAG-style، حافظه سطح توکن (Token-level Memory) و مدیریت حافظه ساختاریافته است.
5. خودبهبودی (Self-Improvement)
عامل میتواند بر اساس تجربههای گذشته، رفتار خود را بازبینی و اصلاح کند.
این مفهوم در برخی پژوهشها با نام Reflection Loop شناخته میشود.
RL به عاملها اجازه میدهد تا از طریق حلقههای بازخورد داخلی و بازتاب مداوم از اشتباهات خود بیاموزند. این میتواند شامل خودتصحیح کلامی (Verbal Self-correction) در زمان استنتاج، یا درونیسازی خودتصحیح (Internalizing Self-correction) از طریق بهروزرسانیهای مبتنی بر گرادیان (مانند KnowSelf) باشد.
6. ادراک و تعامل (Perception & Interaction)
عامل تنها تولیدکننده متن نیست، بلکه درککننده محیط و تعاملکننده فعال با انسانها یا عاملهای دیگر است.
RL ادغام ادراک بصری (Vision) با LLMها را فعال میکند و از ادراک منفعل به شناخت بصری فعال حرکت میکند، که با پاداشهای قابل تأیید (verifiable rewards) هدایت میشود. این امر شامل زمینهسازی (Grounding) و استفاده از ابزارهای بصری است.
کاربردهای Agentic RL در دنیای واقعی
جستوجو و پاسخگویی هوشمند
عاملهای زبانی میتوانند برای جستوجوی اینترنت، خلاصهسازی و پاسخ به پرسشها با دقت بالاتر آموزش ببینند. این عاملها فراتر از بازیابی ساده اطلاعات، به سمت تحقیقات پیچیده چندمرحلهای حرکت میکنند. RL برای بهینهسازی تولید پرسوجو و هماهنگی جستجو-استدلال در تعامل با APIهای وب (مانند DeepRetrieval و Search-R1) یا دانش داخلی LLM استفاده میشود.
تولید و اشکالزدایی کد
ترکیب LLM و RL در ابزارهایی مانند Copilot و ChatGPT Code Interpreter به مدلها اجازه داده تا کدها را بر اساس بازخورد بهبود دهند. اجرای صریح و قابل تأیید کد، این حوزه را به یک بستر ایدهآل برای Agentic RL تبدیل کرده است. RL برای بهبود تولید کد (با پاداشهای مبتنی بر نتیجه نهایی یا پاداشهای مبتنی بر فرآیند مانند StepCoder)، پالایش کد تکراری (مانند RLEF)، و مهندسی نرمافزار خودکار (SWE) برای وظایف طولانیمدت (مانند DeepSWE) استفاده میشود.
استدلال ریاضی و منطقی
در زمینههای ریاضی، عامل میتواند استدلال مرحلهبهمرحله انجام دهد و از نتایج قبلی برای حل مسائل جدید استفاده کند. RL به طور گسترده برای استدلال ریاضیاتی، هم در حوزه غیررسمی (مانند حل مسائل کلامی با ابزارهایی مانند پایتون) و هم در حوزه رسمی (مانند اثبات قضیه با Lean یا Coq) به کار میرود. برای استدلال رسمی، بازخورد دودویی صحت مکانیکی (machine-verifiable correctness) به عنوان پاداش اصلی RL عمل میکند.
ناوبری رابطهای کاربری (GUI Navigation)
برخی عاملها یاد میگیرند با رابطهای گرافیکی تعامل کنند، مثلاً کلیک، جستوجو یا پر کردن فرمها را خودکار انجام دهند. RL تعامل با رابطهای کاربری پویا را به عنوان تصمیمگیری متوالی چارچوببندی میکند. این شامل استفاده از RL در محیطهای GUI ایستا و محیطهای تعاملی و آنلاین (مانند WebAgent-R1) برای یادگیری از طریق آزمون و خطا است.
سیستمهای چندعاملی (Multi-Agent Systems)
در این حوزه، چند عامل LLM با هم همکاری یا رقابت میکنند تا به هدفی مشترک برسند.
برای مثال، در پروژههایی مثل AutoGen یا MetaGPT چند عامل هوشمند با تقسیم وظایف، پروژههای پیچیده را اجرا میکنند.
RL برای بهینهسازی سیستمهای چندعاملی مشارکتی به کار میرود، که به عاملها این امکان را میدهد تا الگوهای هماهنگی را به صورت پویا تنظیم کنند و استراتژیهای استدلال خود را بهبود بخشند.
عاملهای تجسمیافته (Embodied Agents)
RL به عنوان یک استراتژی پسآموزش برای مدلهای بینایی-زبان-عمل (VLA) استفاده میشود تا قابلیتهای برنامهریزی، اکتشاف مؤثر، و تعمیمپذیری در سناریوهای ناوبری و دستکاری اشیاء (Manipulation) را افزایش دهد.
ابزارها و محیطهای متنباز (Open-source Frameworks) برای یادگیری تقویتی عاملمحور
چند محیط و چارچوب مهم برای پیادهسازی Agentic RL عبارتاند از:
LangChain و AutoGen برای طراحی عاملهای زبانی.
Gym و PettingZoo برای شبیهسازی تعاملات عاملها.
ReAct Framework برای پیادهسازی حلقهی Plan–Act–Reflect.
MetaGPT برای همکاری چندعاملی.
چالشها و مسیر آینده یادگیری تقویتی عاملمحور
گرچه Agentic RL بسیار امیدبخش است، اما با چالشهایی روبهروست:
تعریف دقیق پاداشها (Reward Design) در محیطهای پیچیده.
اطمینان از ایمنی و اخلاق در رفتار عاملها.
مدیریت هزینههای محاسباتی بالا.
ارزیابی منسجم بین حوزههای مختلف.
آینده این حوزه به سمت ساخت هوشهای تعاملی خودمختار و تطبیقپذیر (Adaptive and Reliable Agentic Intelligence) پیش میرود که میتوانند در محیطهای واقعی و پویا فعالیت کنند.
جمعبندی
یادگیری تقویتی عاملمحور (Agentic Reinforcement Learning for LLMs) نقطهی اتصال بین هوش مصنوعی تعاملی و مدلهای زبانی بزرگ است.
این رویکرد به LLMها اجازه میدهد تصمیم بگیرند، یاد بگیرند و با محیط سازگار شوند — درست مانند یک عامل هوشمند انسانی.
با رشد ابزارها و پژوهشها در این زمینه، Agentic RL میتواند آیندهی نسل جدیدی از هوش مصنوعی خودمختار و چندعاملی را رقم بزند؛ دنیایی که در آن ماشینها نهتنها پاسخ میدهند، بلکه میاندیشند و تصمیم میگیرند.

{kind=link}
بدون دیدگاه