
رباتهای خودبهبود دهنده: ربات هایی که به خود آموزش میدهند!
در این پست از سایت بنو قصد داریم رباتهای خودبهبود دهنده را بررسی کنیم.
تا به حال به این فکر کرده اید که ما چگونه مهارتی را به ربات ها می آموزیم؟ آیا چقدر این کار میتواند برای نیروی انسانی طاقت فرسا و هزینه بر باشد؟ یادگیری مهارتهای پیچیده نیاز به تکرار دارد: امتحان کن، اصلاح کن، سپس دوباره امتحان کن. اما آیا رباتها هم میتوانند از طریق تمرین و تکرار مهارتی را یاد بگیرند بدون نیاز به دخالت انسان؟
چالشهای جمعآوری دادههای رباتیک
بهبود خودمختاری برای رباتها یکی از چالشهای اصلی در زمینه رباتیک است. جمعآوری دادههای رباتیک تحت نظارت انسان بسیار گرانقیمت است. برای مثال، یکی از بزرگترین مجموعه دادههای تعاملی رباتیک که برای پروژههای SayCan و RT-1 استفاده شده، شامل ۱۳۰,۰۰۰ نمایش از وظایفی مانند “برداشتن قوطی نوشابه” است که طی ۱۷ ماه با استفاده از ۱۳ ربات تحت نظارت انسان جمعآوری شده است.
جمعآوری دادهها به صورت خودمختار
حال تصور کنید اگر این رباتها به صورت خودمختار داده جمعآوری میکردند. یک محاسبه ساده نشان میدهد که ۱۳ رباتی که به صورت خودمختار در طول ۱۷ ماه تعامل میکنند، میتوانند بیش از ۱۷ میلیون مسیر جمعآوری کنند، یعنی تا ۱۰۰ برابر بیشتر دادههای تعاملی!
ساخت رباتهای خودمختار
چگونه میتوانیم رباتهای خودمختاری بسازیم که بتوانند به طور معنیداری با محیطهایشان تعامل داشته باشند و از چنین تعاملی بهبود یابند؟ یادگیری تقویتی (Reinforcement Learning) یا به اختصار RL، یک چارچوب طبیعی برای ساخت چنین سیستمهایی ارائه میدهد. در RL، عاملها میتوانند از طریق آزمون و خطا یاد بگیرند.
چالشهای یادگیری تقویتی
متأسفانه، آموزش سیستمهای رباتیک با استفاده از RL هنوز نیاز به نظارت گسترده انسان در طول آموزش دارد. با این حال، پیشرفت در این زمینه میتواند به توسعه سیستمهای رباتیک ماهر از دستکاری تا حرکت منجر شود.
توسعه رباتهای خودمختار که بتوانند به طور موثر با محیط خود تعامل کنند و از تعاملات خود بیاموزند، همچنان یک چالش بزرگ در علم رباتیک است. اما با استفاده از روشهای نوین مانند یادگیری تقویتی، میتوان به پیشرفتهای قابل توجهی دست یافت.



انسانها محیط را برای رباتها به طور مکرر تنظیم مجدد میکنند تا وظایف مربوطه خود را تمرین کنند. مداخلات انسانی برای تنظیم مجدد محیط میتواند به دفعات هر دقیقه یک بار باشد.
یک انسان باید محیط را قبل از هر آزمون وظیفه برای الگوریتمهای فعلی RL تنظیم مجدد کند تا به طور موفقیتآمیز وظیفهای را یاد بگیرد. در واقع، چنین نظارتی گرانقیمت است و مانع از این میشود که رباتها به طور خودمختار یاد بگیرند و بهبود یابند. زیرا تنظیم مجدد محیط میتواند به اندازه خود وظیفه دشوار باشد. به عنوان مثال، یادگیری نحوه باز کردنِ در، نیاز به بستنِ در برای تنظیم مجدد محیط دارد که میتواند به همان اندازه برای ربات سخت باشد. به طور مؤثر، به حداقل رساندن نیاز به نظارت انسانی برای تنظیم مجدد محیطها پس از هر آزمون، برای جمعآوری مجموعه دادههای عظیم ضروری، برای آموزش رباتها بسیار حیاتی است.
در ادامه سه مورد در این زمینه مورد بحث قرار میگیرد:
(الف) EARL نشان میدهد که الگوریتمهای فعلی RL بدون تنظیمات مکرر انسانی مشکل دارند و توضیحی ممکن برای این پدیده ارائه میدهد
(ب) MEDAL یک الگوریتم RL ارائه میدهد که میتواند به صورت کارآمد و خودمختار یاد بگیرد
(ج) رباتهای خودبهبود بر اساس MEDAL یک سیستم ربات واقعی ارائه میدهد که میتواند از تعامل خودمختار با محیط بهبود یابد.
EARL: الگوریتمهای RL بدون تنظیم مکرر محیط شکست میخورند.
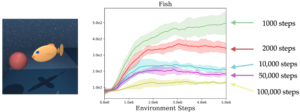
وظیفه یادگیری حرکت ماهی زرد به سمت هدف قرمز را در شکل بالا در نظر بگیرید. یک الگوریتم RL معمولی به صورت اپیزودیک با این وظیفه برخورد میکند، به این معنا که یک عامل تلاش میکند وظیفه را برای تعداد ثابتی از گامها انجام دهد قبل از اینکه در صورت ناموفق بودن، از ادامه دادن صرفنظر کند. نکته مهم این است که بین هر اپیزود، محیط باید بازنشانی شود تا عامل بتواند دوباره تلاش کند. اما اگر به جای بازنشانی محیط، به سادگی به عامل اجازه دهیم به عمل خود ادامه دهد، چه اتفاقی میافتد؟ برای آزمون این فرضیه، آزمایشی ترتیب داده شد که عملکرد عامل را که به عنوان طول اپیزود افزایش مییابد، اندازهگیری میکند. مشاهده شد که سیاست یادگرفته شده به طور قابل توجهی بدتر میشود وقتی که محیط کمتر بازنشانی میشود. این مسئله محور مشکل ما را نشان میدهد: یک الگوریتم RL معمولی نیاز دارد که وظیفه را چندین بار تکرار کند و بازنشانی محیط نیازمند نظارت انسانی مداوم در طول آموزش است!
چرا بازنشانی کمتر محیط به سیاستهای بدتر منجر میشود؟ پاسخ این است که وقتی محیط به طور مکرر بازنشانی نمیشود، عامل که آموزش دیده تا یک تابع پاداش(reward function) را به حداکثر برساند، تمایل دارد که در حالتهای با پاداش بالا پرسه بزند. این امر منجر به عدم کاوش کافی در کل فضا و در نتیجه دادههای ناکافی برای یادگیری یک سیاست کارآمد میشود. با این حال، بازنشانی مکرر محیط در دنیای واقعی عملی نیست. برای کمک به طراحی الگوریتمهای مناسب برای یادگیری در دنیای واقعی، ما مشکل یادگیری تقویتی خودمختار را پیشنهاد دادیم، که در آن یک عامل موظف است در محیطی با حداقل بازنشانیهای مکرر یک سیاست مؤثر را یاد بگیرد. ما یک بنچمارک از محیطهای شبیهسازی شده چالشبرانگیز معرفی کردیم تا عملکرد بدون مداخلات مکرر برای بازنشانی محیط را ارزیابی کنیم. متوجه شدیم که الگوریتمهای RL موجود در این بنچمارکها مشکل دارند و فضای زیادی برای بهبود وجود دارد.
حالا یک راه حل پیش روی ماست و میرویم تا با MEDAL آشنا شویم!
(Matching Expert Distributions for Autonomous Learning)MEDAL: اگر سیاستی برای لغو کار یاد بگیریم چه؟
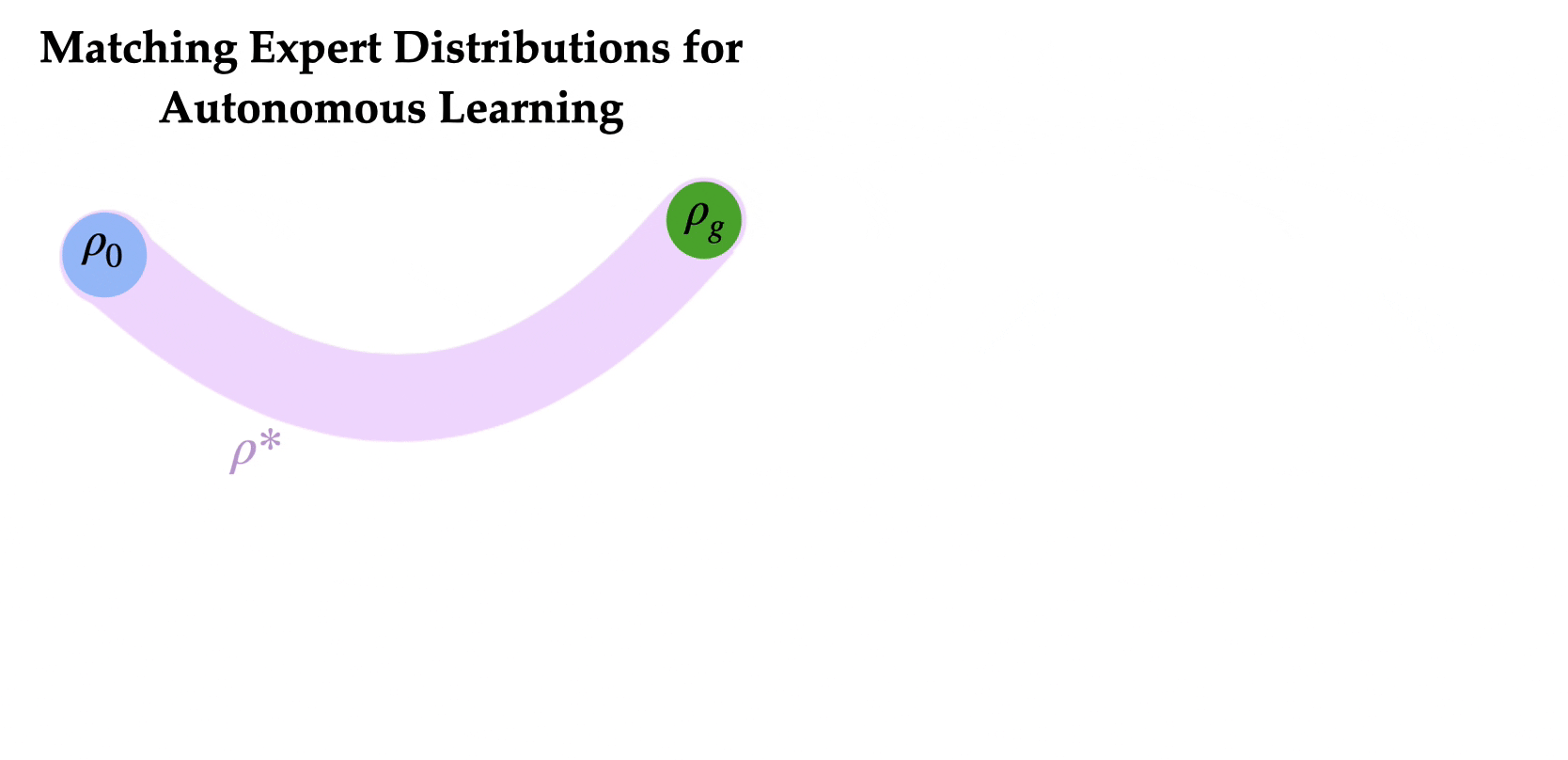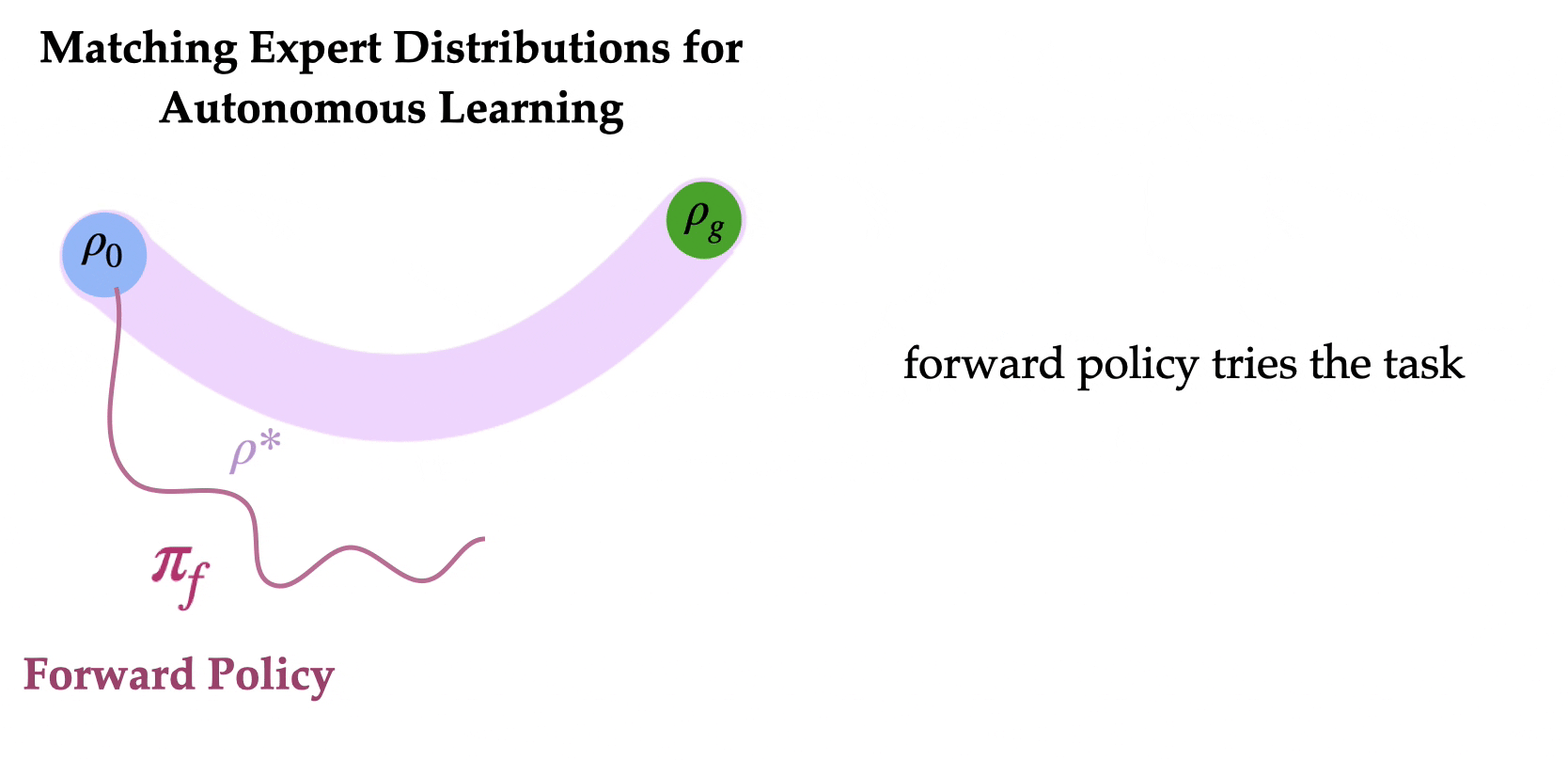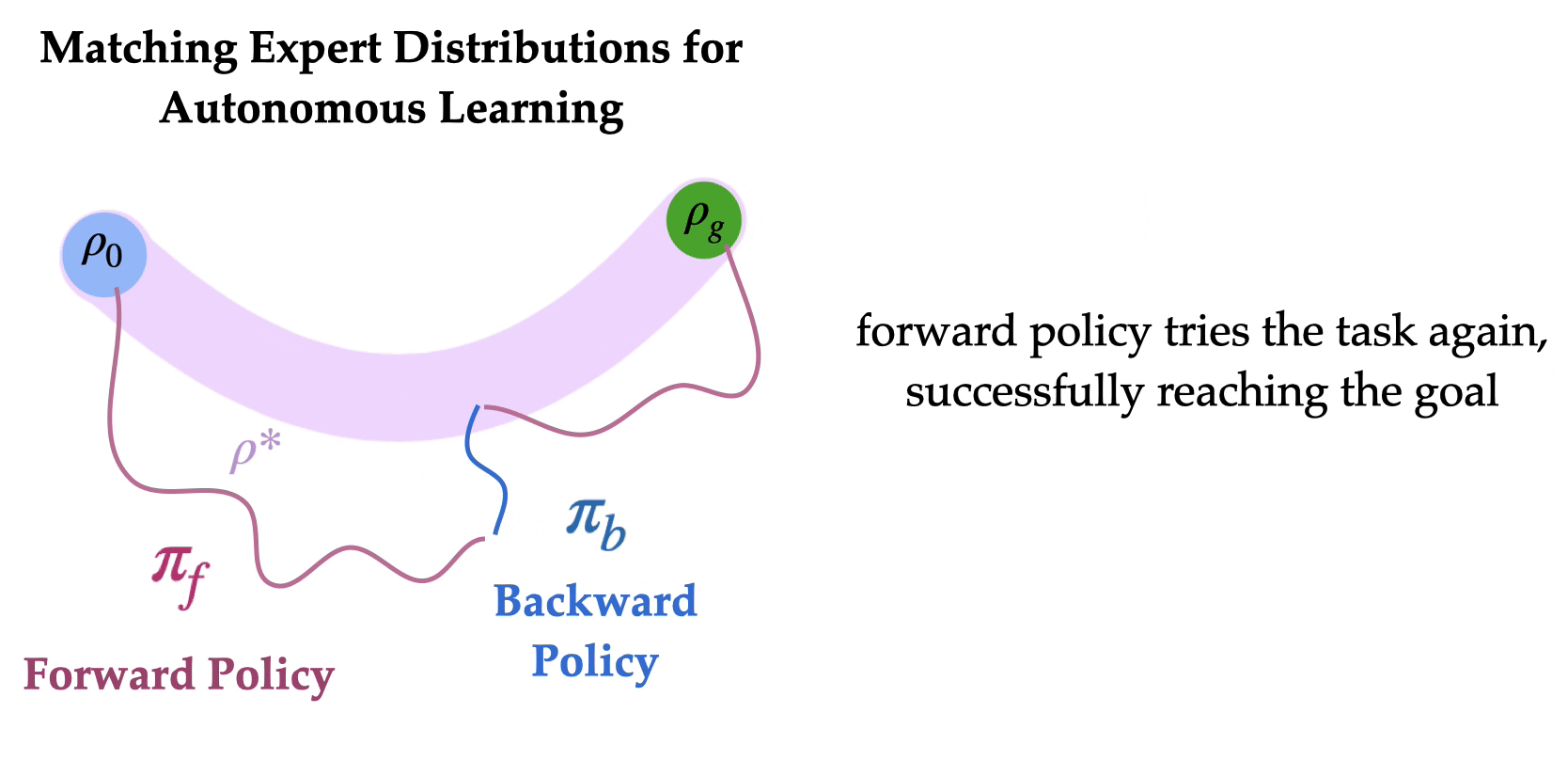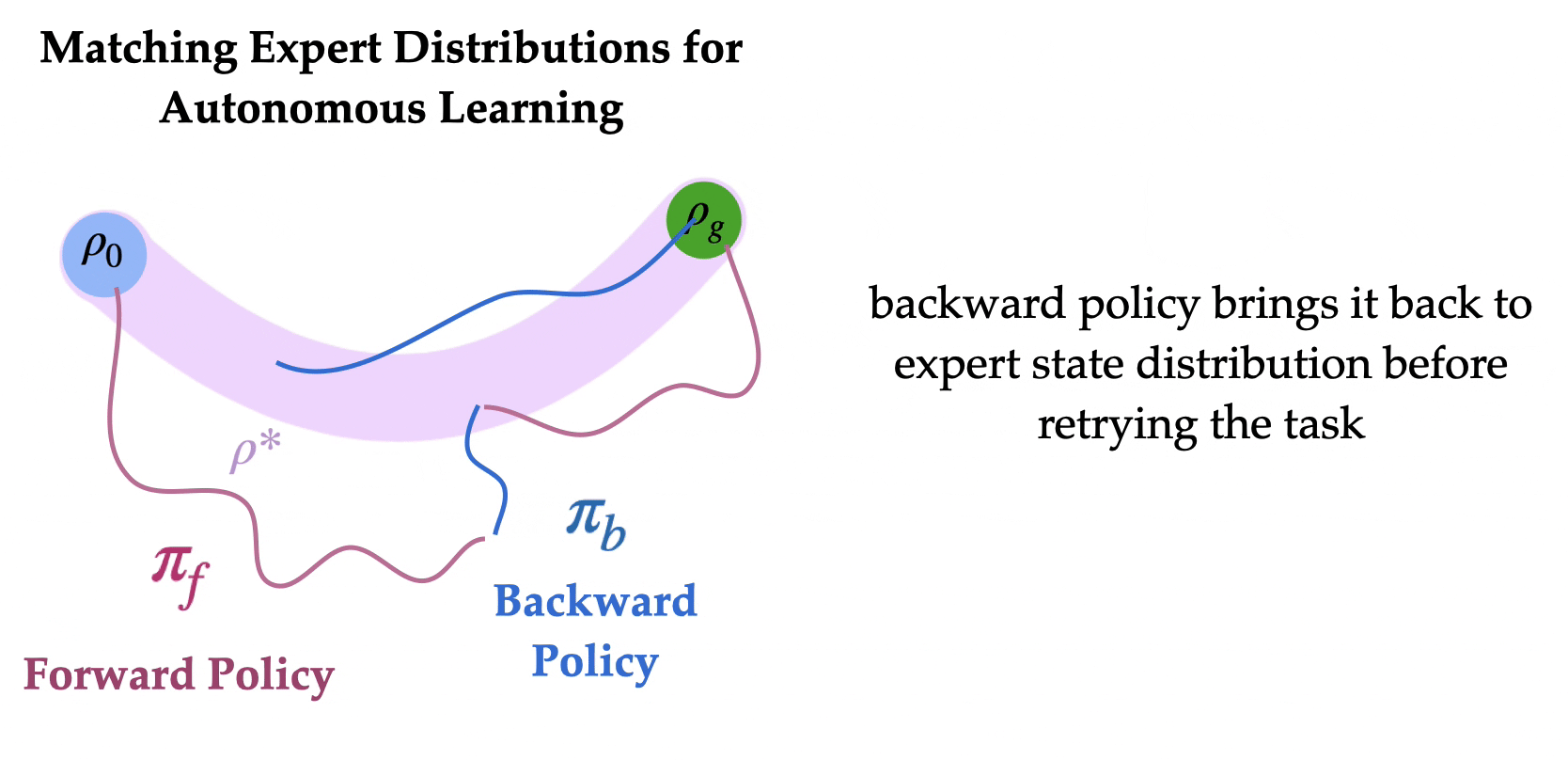
مروری بر MEDAL برای آموزش عوامل RL به طور مستقل با حداقل مداخلات انسانی برای تنظیم مجدد محیط.
چگونه میتوانیم ربات ها را بدون مداخلات مکرر انسانی آموزش دهیم؟
ایده کلیدی این است که محیط را به گونهای بازنشانی کنیم که نیازی به مداخلات مکرر انسانی نباشد. به طور خاص، ربات ما دو سیاست یاد میگیرد: یک سیاست به جلو برای انجام وظیفه و یک سیاست به عقب برای لغو وظیفه. این دو سیاست به ترتیب به یکدیگر متصل شدهاند تا به عامل امکان دهند که به طور خودمختار با حداقل مداخلات انسانی آموزش ببیند. سیاست به عقب باید چه چیزی را بهینه کند؟ به نظر میرسد طبیعی باشد که سیاست به عقب را برای رسیدن به توزیع حالتهای اولیه آموزش دهیم، به طوری که سیاست به جلو بتواند وظیفه را به طور مکرر از توزیع حالتهای اولیه امتحان کند. آیا میتوانیم سیاست به عقب را به گونهای یاد بگیریم که به سیاست به جلو کمک کند تا به طور مؤثرتری یاد بگیرد؟
برای یادگیری مؤثر سیاست به جلو برای حل وظیفه، یادگیری ربات اغلب نیاز به مجموعهای کوچک از نمایشهای کارشناسی در مورد “چگونگی حل وظیفه” دارد. یافتن مسیر اولیه به هدف میتواند بسیار زمانبر باشد (یعنی “مسئله کاوش”) و نمایشهای کارشناسی میتوانند به طور قابل توجهی سرعت یادگیری را با مقابله با این چالش کاوش افزایش دهند. بینش کلیدی ما این است که اگر چنین نمایشهای کارشناسی در دسترس باشد، (الف) یادگیری سیاست به عقب برای رسیدن به هر یک از حالتهایی که کارشناس در نمایشها بازدید کرده است، میتواند آسانتر از یادگیری برای رسیدن به فقط توزیع حالتهای اولیه باشد و (ب) حالتهای کارشناسی توزیع مؤثرتری از حالتهای شروع برای یادگیری سیاست به جلو فراهم میآورند، زیرا عامل میتواند وظیفه را از حالتهای مختلف که از آسان تا دشوار متغیر هستند امتحان کند. سیاست به جلو میتواند یاد بگیرد که چگونه وظیفه را از حالتهای نزدیک به هدف (“حالتهای اولیه آسان”) حل کند و از موفقیتها برای یادگیری از حالتهای دورتر از هدف (“حالتهای اولیه دشوار”) استفاده کند.
این رویکرد به عنوان انگیزهای برای MEDAL (مطابقت توزیعهای کارشناسی برای یادگیری خودمختار) عمل میکند، جایی که عامل یک سیاست به جلو را برای حداکثر کردن پاداشهای وظیفه یاد میگیرد و سیاست به عقب یاد میگیرد که به طور یکنواخت حالتهایی که کارشناس بازدید کرده است را پوشش دهد، بدون نیاز به توابع پاداش اضافی برای آموزش سیاست به عقب. در واقع، MEDAL به طور قابل توجهی هم کارایی یادگیری و هم عملکرد نهایی سیاستهای یادگرفته شده را بهبود میبخشد.
چگونه میتوانیم یک سیستم رباتیک خودبهبود دهنده بسازیم؟
حالا که یک الگوریتم یادگیری کارآمد بدون نیاز به مداخلات مکرر انسانی داریم، میتوانیم به هدف خود برای ساخت رباتهای خودبهبود دهنده برگردیم! یادگیری رباتها در دنیای واقعی دو چالش اضافی به غیر از کمبود نظارت برای بازنشانی محیطها دارد:
۱. چالش اول: نیاز به یادگیری از دادههای حسی خام
– حالتهای کمبعدی مانند مختصات اشیاء برای هر وظیفه گرانقیمت هستند و نیازمند مهندسی دقیق (شامل شناسایی اشیاء، کالیبراسیون و غیره) هستند. سیستمهای رباتیک باید بتوانند به طور مستقیم از دادههای حسی خام، مانند ورودیهای تصویری، یاد بگیرند.
۲. چالش دوم: عدم وجود برچسبهای پاداش در دنیای واقعی
– در دنیای واقعی برچسبهای پاداش وجود ندارد و رباتها باید بدون توابع پاداش خاص وظیفه که به طور مهندسی طراحی شدهاند، یاد بگیرند. این بدان معناست که رباتها باید توانایی یادگیری از تجربیات و تعاملات خود را بدون نیاز به پاداشهای مشخص برای هر وظیفه داشته باشند.

مروری بر MEDAL++: یک الگوریتم عملی قابل تحقق برای آموزش ربات ها به صورت مستقل.
برای حل این مسائل، ما ++MEDAL را پیشنهاد میکنیم تا MEDAL را برای سیستمهای رباتیک خودبهبود دهنده تطبیق داده و بهبود بخشد!
برای آموزش مؤثر سیاستهای خود از ورودیهای پیکسلی، از تکنیکهای تقویتی مانند برش تصادفی و تغییر موقعیت استفاده میکنیم تا یادگیری را منظم کنیم. نکته مهم این است که چگونه میتوانیم بدون پاداشهای وظیفه یاد بگیریم؟ نمایشهای کارشناسی دوباره به کمک میآیند! ما میتوانیم از حالتهای پایانی در نمایشهای کارشناسی به عنوان نمایندهای برای حالتهای هدف استفاده کنیم و سیاست به جلو را برای رسیدن به حالتهای “مشابه” این حالتها پاداش دهیم. شباهت با استفاده از یک طبقهبند آموزش دیده به روش مخالف اندازهگیری میشود، بر اساس این ایده که شباهت بصری با نزدیکتر شدن ربات به هدف افزایش مییابد. بنابراین، نمایشهای کارشناسی به عنوان نظارت برای آموزش هر دو سیاست به جلو و سیاست به عقب عمل میکنند.
محققان از ++MEDAL برای آموزش یک بازوی فرانکا به طور خودمختار برای انجام چندین وظیفه manipulative استفاده کردند که نمونههایی از آن در شکل زیر نشان داده شده است. با شروع از تنها 50 نمایش کارشناسی، بازوی رباتی توانست نرخ موفقیت را بین 30-70% از طریق (عمدتاً) تمرین خودمختار در طی 20 ساعت (با کمتر از 50 مداخله برای بازنشانی محیط!) بهبود بخشد. به طور کلی، ++MEDAL به یک الگوی یادگیری اجازه میدهد که در آن یک کارشناس از طریق تعداد کمی از نمایشها دستورالعمل را ارائه دهد و ربات میتواند به طور خودمختار پس از آن تمرین کند.

آیا به آنجا رسیدیم؟
این دوران برای مقیاسپذیری یادگیری رباتها بسیار هیجانانگیز است و جمعآوری و آموزش بر روی مجموعههای داده بزرگ در قلب این موضوع قرار دارد. تحقیقات اخیر شروع به استفاده از منابع داده در مقیاس اینترنتی (مانند یوتیوب) برای تقویت یادگیری رباتها کردهاند. در حالی که این منابع برای ایجاد نمایههایی از جهان اهمیت دارند، دادههای رباتهای تجسمشده برای یادگیری مهارتهای پیچیده بسیار حیاتی هستند زیرا اطلاعاتی درباره تعاملات ربات با محیط بدون هیچ گونه تغییر دامنه ارائه میدهند. همانطور که در این پست اشاره کردیم، میتوان این دادهها را از طریق چارچوبی که پیشنهاد شد، برای یادگیری تقویتی خودمختار (RL) به میزان زیادی مقیاسپذیر کرد.
با این حال، کار ما تنها شروعی برای پرداختن به این مشکل چالشبرانگیز است و سوالات و مسیرهای بهبودی زیادی وجود دارد:
خودمختاری مشترک: در حالی که در این مقاله بر روی خودمختاری و کاهش نیاز به بازنشانی محیطها تأکید کردهایم، نظارت انسانی واقعاً برای یادگیری رباتها بسیار مفید است. با این حال، استفاده از آن برای بازنشانی مکرر محیطها به نظر نمیرسد بهترین استفاده از این نظارت باشد. تخصیص مؤثر و مقیاسپذیر بین اشکال مختلف نظارت انسانی، مانند بازنشانی محیطها، برچسبگذاری پاداشها یا نمایشهای کارشناسی وظیفه، چیست؟
مدیریت غیرقابلیت بازگشت: به طور اجتنابناپذیر، عاملهای رباتیک با وضعیتهای غیرقابل بازگشت مواجه خواهند شد که در آنها انسانها باید مداخله کنند، به عنوان مثال، بیرون راندن یک لیوان از دسترس بازوی ربات. ما یک تلاش اولیه با “PAINT” به عنوان چارچوبی برای یادگیری زمان درخواست کمک از انسان انجام دادیم، اما هنوز فضای زیادی برای بهبود استفاده از نظارت انسانی وجود دارد!
استقرار خودمختار: رباتهای مستقر به طور خودمختار به طور اجتنابناپذیر با وضعیتهای جدیدی که در دادههای آموزشی وجود ندارد، مواجه خواهند شد. آیا آنها میتوانند به طور خودمختار بازگردند اگر گیر کنند (برای مثال، یک ربات تحویل در آخرین کیلومتر که در یک چاله گیر کرده است) و به بهینهسازی اهداف خود ادامه دهند؟
معیارهای بهتر: “EARL” یک معیار کوچک با چالشهای زیادی از یادگیری تقویتی خودمختار است که هنوز پوشش داده نشده است (برای مثال، وضعیتهای غیرقابل بازگشت). ایجاد محیطهای متنوع و بیانگر میتواند به توسعه الگوریتمی بهتر کمک کند و درک تعادلات بین اشکال و مقادیر نظارت را بهبود بخشد.
جمعبندی: برای دستیابی به رباتهای کاملاً قادر که بتوانند به طور خودمختار در محیطهای غیرساختاریافته مانند آشپزخانهها، خانهها و دفاتر عمل کنند، ممکن است مفید باشد که به طور مستقیم در دنیای واقعی به یادگیری خودمختار بپردازیم. فکر کردن به آنچه که لازم است رباتها بتوانند به طور ۲۴x۷ کار کنند و دادهها را در محیطهای متنوع جمعآوری کنند تا واقعاً به تحقق این دیدگاه نزدیک شویم، ارزشمند است.
این پست مرکز هوش مصنوعی بنو برگرفته از مقاله ی زیر است، برای مطالعه ی بیشتر به لینک گذاشته شده مراجعه کنید:
Self-Improving Robots: Embracing Autonomy in Robot Learning | SAIL Blog (stanford.edu)
برای دیدن پست های بیشتر در زمینه ی هوش مصنوعی به اینجا (وبلاگ هوش مصنوعی بنو) سر بزنید!


{kind=link}
بدون دیدگاه