
چگونه مدلهای زبانی خودشان را بهتر میکنند؟
از مدلهای بزرگ تا زمینههای هوشمند
در دنیای امروز، مدلهای زبانی بزرگ (LLMها) ستون فقرات هوش مصنوعی هستند.اما پژوهشگران فهمیدهاند که افزایش تعداد پارامترها همیشه به معنای افزایش هوشمندی نیست.هوش واقعی زمانی شکل میگیرد که مدل بداند چطور از تجربههایش یاد بگیرد.اینجا جایی است که مهندسی زمینه (Context Engineering) وارد بازی میشود.به جای آموزش دوبارهی مدل یا تغییر وزنها، مهندسی زمینه فقط ورودی مدل را تغییر میدهد —
با افزودن دستورالعملهای دقیقتر، شواهد جدید و تجربههای قبلی.در مقاله ی جدیدی که پژوهشگران دانشگاه استنفورد و SambaNova با الهام از این ایده، چارچوبی طراحی کردند به نامACE (Agentic Context Engineering) — روشی که به مدلها اجازه میدهد زمینههای خود را بسازند، بازتاب دهند و اصلاح کنند.
مشکل کجاست؟ چرا به ACE نیاز داریم؟
در مهندسی زمینه، بهجای تغییر وزنها یا آموزش مجدد مدل، تنها زمینهی ورودی به مدل اصلاح میشود. با افزودن دستورالعملهای دقیقتر، مثالهای تازه، شواهد جدید و بازخوردهای تجربی، میتوان مسیر تفکر مدل را تغییر داد و آن را به استدلالهای عمیقتر هدایت کرد.
اما این روش سنتی نیز محدودیتهایی دارد. در شیوههای قدیمیتر مانند GEPA یا Dynamic Cheatsheet دو مشکل اساسی دیده شد:
۱. سوگیری به اختصار (Brevity Bias)
این روشها معمولاً سعی میکردند زمینه را خلاصه و عمومی نگه دارند.
اما وقتی جزئیات تخصصی حذف میشود، مدل توانایی استدلال دقیق را از دست میدهد.
در واقع، خلاصهسازی بیش از حد باعث میشود مدل بهتر حرف بزند، اما کمتر بفهمد.
۲. فروپاشی زمینه (Context Collapse)
وقتی مدل بارها زمینه را بازنویسی میکند، معمولاً آن را کوتاهتر و سادهتر مینویسد.
در یکی از آزمایشها، پژوهشگران دیدند که زمینه از ۱۸ هزار توکن به فقط ۱۲۲ توکن کاهش یافت،
و دقت مدل از ۶۶٪ به ۵۷٪ افت کرد.
به این ترتیب، مدل بخش زیادی از دانشی را که خودش ساخته بود، از دست داد.
ACE چیست و چطور کار میکند؟
پژوهشگران دانشگاه استنفورد و شرکت SambaNova برای حل این مشکلات، چارچوبی تازه معرفی کردند به نام ACE (Agentic Context Engineering) — روشی که به مدل اجازه میدهد خودش زمینهی خود را بسازد، بازتاب دهد و اصلاح کند.
مقاله ی “ASI‑ARCH: لحظهی AlphaGo در طراحی خودکار معماری شبکه عصبی”حتما مطالعه کنید.
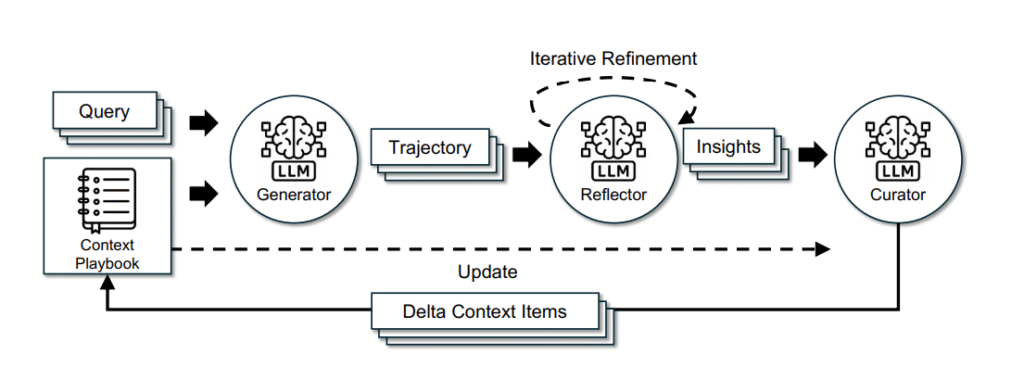
ACE زمینه را مانند یک دفترچه زنده (Evolving Playbook) میبیند؛ جایی که مدل میتواند تجربههایش را ثبت کند، از عملکرد خود درس بگیرد و بهصورت تدریجی تکامل یابد. بهجای بازنویسی کامل، ACE فقط بخشهایی را که نیاز به اصلاح دارند تغییر میدهد.
ساختار ACE: سه نقش برای یک ذهن خودآگاه
ACE از سه بخش اصلی تشکیل میشود که با هم کار میکنند تا یادگیری واقعی اتفاق بیفتد:
۱. مولد (Generator)
مولد ایده تولید میکند. برای هر مسئله، مسیرهای استدلال و پاسخهای احتمالی را میسازد.
۲. بازتابگر (Reflector)
بازتابگر ماژولی است که خروجیهای تولیدشده توسط هوش مصنوعی را تحلیل کرده، نقاط قوت و ضعف آنها را شناسایی میکند و بازخوردی هوشمند برای بهبود نسلهای بعدی ارائه میدهد.
۳. گردآورنده (Curator)
گردآورنده این درسها را در قالب نکات مشخص و قابل استفاده ذخیره میکند.
او دادهها را مرتب میکند، تکراریها را حذف میکند و فقط اطلاعات مفید را در دفترچه نگه میدارد.
به زبان ساده:
مولد عمل میکند ، بازتاب گر یاد می گیرد و گردآورنده حافظه می سازد.
ویژگیهای کلیدی ACE
بهروزرسانی تدریجی (Incremental Delta Updates)
ACE هیچوقت زمینه را از نو نمینویسد.
فقط بخشهای مرتبط را تغییر میدهد تا هم هزینه و زمان کاهش یابد و هم حافظه حفظ شود.
هر «دلتا» یک یادداشت کوچک از تجربه است — مثل «این راهحل جواب داد» یا «این اشتباه باعث خطا شد».
مقاله “یادگیری تقویتی عاملمحور برای مدلهای زبان بزرگ (Agentic RL – Reinforcement Learning for LLMs): گام بعدی هوش مصنوعی خودمختار” را حتما مطالعه کنید.
رشد و پالایش (Grow and Refine)
ACE همزمان رشد میکند و خود را اصلاح میکند.
وقتی زمینه بیش از حد بزرگ شود، سیستم ورودیها را بررسی میکند، تکراریها را حذف میکند و فقط مفیدترین نکات را نگه میدارد.
به این ترتیب، دفترچه مدل همیشه تازه و کاربردی میماند.
بازتاب چندمرحلهای (Multi-Epoch Reflection)
بازتابگر فقط یکبار بازبینی نمیکند.
او در چند مرحله روی همان تجربهها کار میکند تا درسهای عمیقتر استخراج شود.
این روند دقیقاً شبیه مرور چندبارهی یک تجربه برای یادگیری بهتر است.
عملکرد و نتایج
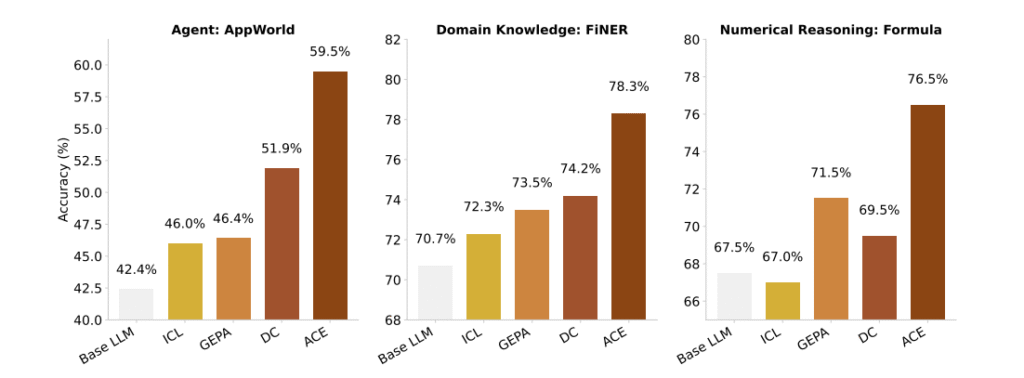
پژوهشگران ACE را روی دو دسته وظیفه آزمایش کردند:
عاملهای زبانی (Agents) و تحلیل مالی.
عاملهای زبانی (AppWorld Benchmark)
در آزمایشهای AppWorld، ACE دقت مدل را تا ۱۷٪ نسبت به بهترین روشهای قبلی افزایش داد.
مدل حتی بدون دادههای برچسبخورده یاد گرفت و عملکردش با GPT-4.1 برابری کرد،
در حالیکه فقط از مدل متنباز DeepSeek-V3.1 استفاده میکرد.
ACE توانست با استفاده از بازخورد طبیعی (مثل موفقیت یا شکست اجرای کد)، خودش را تنظیم کند.
به این ترتیب، مدل بهجای تکرار اشتباهها، از آنها درس گرفت.
استدلال مالی (Financial Reasoning)
در بنچمارکهای FiNER و Formula، ACE میانگین دقت را ۸٫۶٪ افزایش داد.
مدل یاد گرفت مفاهیم مالی، ساختارهای عددی و قوانین XBRL را در حافظهی زمینهای خود ذخیره کند و از آنها در مسائل جدید استفاده کند.
نتیجه این بود که مدل نهتنها سریعتر پاسخ داد، بلکه تصمیمهای دقیقتری هم گرفت.
بهرهوری و هزینهACE علاوه بر دقت بالا، بهرهوری فوقالعادهای دارد:
| شاخص مقایسه | GEPA | ACE | کاهش |
|---|---|---|---|
| زمان انطباق | ۵۳,۸۹۸ ثانیه | ۹,۵۱۷ ثانیه | 🔻 ۸۲٪ |
| تعداد اجراها | ۱۴۳۴ | ۳۵۷ | 🔻 ۷۵٪ |
| هزینه توکنی (FiNER) | ۱۷.۷ دلار | ۲.۹ دلار | 🔻 ۸۴٪ |
مدل با هزینه کمتر، سرعت بالاتر و حافظهای مؤثرتر عمل میکند.
ACE ثابت کرد که میتوان مدلهای زبانی را بدون آموزش مجدد، بهینه و توانمند کرد.
اهمیت ACE در آیندهی یادگیری هوش مصنوعی
ACE افق تازهای را در مسیر هوش مصنوعی خودآموز (Self-Learning AI) میگشاید.
بهجای آموزش مجدد سنگین، مدل میتواند بهصورت پیوسته و تجربی یاد بگیرد. این قابلیت در بسیاری از حوزهها کاربرد حیاتی دارد:
ساخت عاملهای خودبهبود در محیطهای زنده
یادگیری بدون دادهی برچسبخورده
فراموشی انتخابی اطلاعات نادرست
یادگیری پیوسته برای مدلهای در حال استفاده
ACE در واقع به مدلها ذهنی فعال و خودبازتابگر میدهد — ذهنی که میتواند از گذشته درس بگیرد، آینده را پیشبینی کند و دانش خود را بهصورت طبیعی تکامل دهد.
محدودیتها و چالشها
ACE برای عملکرد عالی به یک بازتابگر قوی نیاز دارد.
اگر Reflector نتواند از دادهها درس مفید استخراج کند، زمینه آلوده یا بیاثر میشود.
همچنین در وظایف ساده یا کوتاه، مثل پاسخ به سؤالات عمومی، ACE ممکن است ضرورتی نداشته باشد.
اما در پروژههایی که استدلال، تعامل چندمرحلهای یا تخصص دامنهای نیاز دارند، ACE درخشان عمل میکند.
جمع بندی
آموزش ACE نشان میدهد که آیندهی هوش مصنوعی در بزرگتر کردن مدلها نیست، بلکه در هوشمندتر کردن زمینههاست.
مدلهایی که بتوانند از تجربهی خود یاد بگیرند، اشتباهاتشان را بفهمند و دانششان را بهمرور پالایش کنند، گام بعدی در تکامل هوش مصنوعی خواهند بود.
با این رویکرد، LLMها از ابزارهای ایستا به عاملهای زنده و پویا تبدیل میشوند — سیستمهایی که نهفقط حرف میزنند، بلکه میفهمند، میآموزند و رشد میکنند.
بهجای آموزش دوباره، باید به مدل یاد بدهیم خودش آموزش ببیند.
این، مسیر آیندهی هوش مصنوعی خودتکاملی است.

: روشی نو برای مدلهای زبانی){kind=link}
خیلی مفید بود مچکرم