مروری جامع بر مدلهای زبانی بزرگ علمی (Sci-LLMs): از داده تا کشف علمی خودکار
مدلهای زبانی بزرگ (LLMs) مثل GPT، در چند سال اخیر تحول بزرگی در هوش مصنوعی ایجاد کردهاند. اما وقتی این مدلها وارد دنیای علم میشوند، به شکل مدلهای زبانی بزرگ علمی (Sci-LLMs) در میآیند که توانایی تحلیل و پردازش دادههای پیچیده علمی را دارند.
این مدلها نهتنها متون علمی را میفهمند، بلکه میتوانند دادههای چندوجهی مثل فرمولها، تصاویر میکروسکوپی، طیفهای شیمیایی و حتی دادههای ژنومی را هم پردازش کنند.
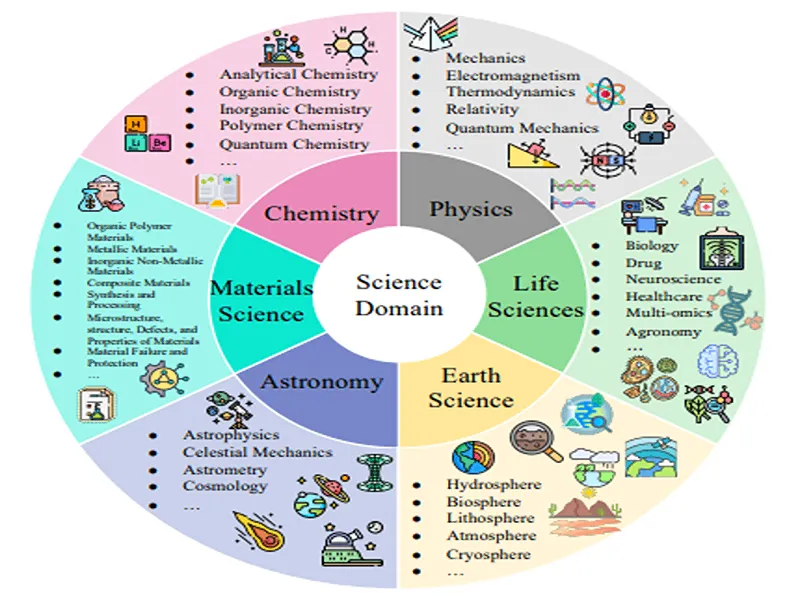
یکی از موضوعات کلیدی مقاله این است که دادههای علمی با دادههای عمومی (مثل متنهای وب یا شبکههای اجتماعی) خیلی متفاوت هستند. دادههای علمی:
ناهمگن و چندمدلی هستند (مثلا در شیمی هم معادله داریم، هم تصویر میکروسکوپی و هم جدول آزمایش).
چندمقیاسی هستند (از مقیاس کوانتومی در فیزیک تا مقیاس کیهانی در نجوم).
دارای عدم قطعیت هستند (مثلا در آزمایشهای فیزیکی همیشه خطای اندازهگیری وجود دارد).
به همین دلیل، ساخت Sci-LLMs بسیار پیچیدهتر از LLMهای عمومی است.
چالش اصلی: دادههای علمی
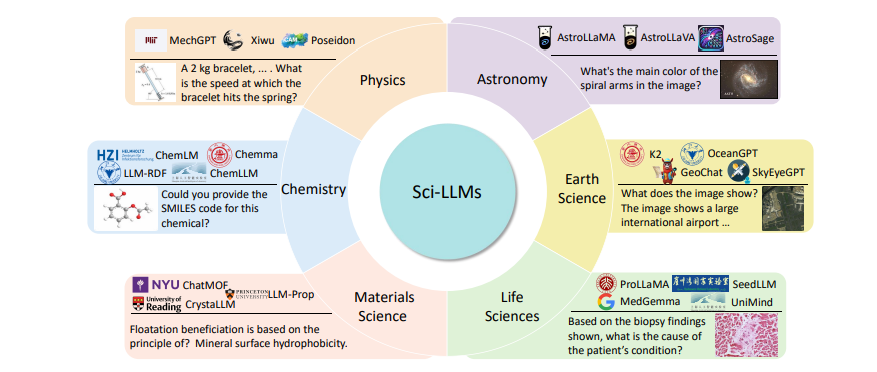
همچنین، بیش از ۲۷۰ دیتاست آموزشی و ۱۹۰ دیتاست ارزیابی بررسی شده و نشان داده میشود که چرا دادههای علمی با ماهیت ناهمگن و چندلایهای خود نیازمند روشهای خاص برای بازنمایی و استدلال هستند. مقاله همچنین تغییر رویکرد در ارزیابی این مدلها را از آزمونهای ایستا به سمت ارزیابیهای فرآیندی و اکتشافی نشان میدهد.
در نهایت، نویسندگان به ظهور یک روش جدید اشاره میکنند که در آن عوامل هوشمند مبتنی بر Sci-LLMs بهطور خودکار آزمایش میکنند، اعتبارسنجی میکنند و به یک پایگاه دانش پویا و زنده کمک میکنند.
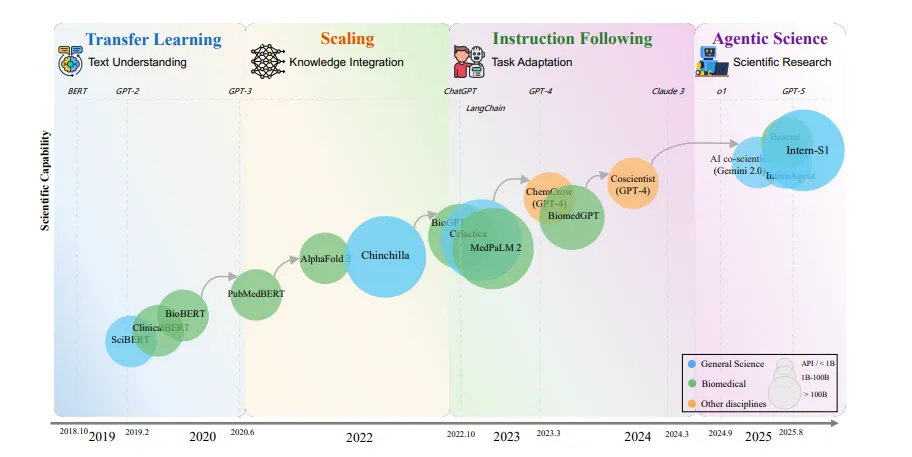
تحول مراحل Sci-LLMs (۲۰۱۸ تا ۲۰۲۵)
نویسندگان مقاله چهار مرحله اصلی را در تکامل مدلهای زبانی بزرگ علمی معرفی میکنند:
یادگیری انتقالی (۲۰۱۸–۲۰۲۰)
مدلهایی مثل SciBERT و BioBERT که روی مقالات علمی آموزش داده شدند.
تمرکز اصلی: فهم بهتر متون علمی.
مقیاسپذیری (۲۰۲۰–۲۰۲۲)
مدلهایی مثل GPT-3 و Galactica با میلیاردها پارامتر.
توانایی ترکیب دانشهای مختلف و ایجاد بینش جدید.
پیروی از دستورالعمل (۲۰۲۲–۲۰۲۴)
مدلهایی مثل MedPaLM-2 و SciGLM که توانستند در آزمونهای پزشکی و علمی عملکردی در سطح متخصصان نشان دهند.
تمرکز اصلی: تعامل طبیعیتر با پژوهشگران.
علم عاملمحور (۲۰۲۳ تا امروز)
نسل جدید مدلها مثل Intern-S1 یا سیستمهای چندعاملی (Multi-Agent) که میتوانند بهطور خودکار فرضیهسازی، طراحی آزمایش و تحلیل داده انجام دهند.
این یعنی هوش مصنوعی به یک همکار پژوهشی واقعی تبدیل میشود.
مقاله بیش از ۲۷۰ دیتاست آموزشی و ۱۹۰ دیتاست ارزیابی را بررسی کرده است. این دیتاستها از حوزههای مختلف مثل:
فیزیک و شیمی (فرمولها، طیفها، دادههای آزمایشگاهی)
علوم زیستی و پزشکی (دادههای ژنومی، تصاویر پزشکی، مقالات پزشکی)
نجوم و زمینشناسی (مشاهدات تلسکوپی، تصاویر ماهوارهای، دادههای اقلیمی)
نویسندگان نشان میدهند که برای موفقیت Sci-LLMs باید هم کیفیت دادهها (دقت، کامل بودن، بهروز بودن) تضمین شود و هم روشهای هوشمندانه برای ترکیب دادههای چندمنبعی ایجاد گردد.
ارزیابی مدلهای زبانی بزرگ علمی
یکی دیگر از نقاط قوت مقاله بررسی روشهای ارزیابی است. برخلاف آزمونهای ساده در NLP، در علوم نیاز داریم بدانیم که آیا مدل میتواند:
فرضیه علمی درست تولید کند.
قوانین علمی (مثل قوانین فیزیک و شیمی) را رعایت کند.
در آزمایشهای شبیهسازیشده، نتایج معتبر و تکرارپذیر ارائه دهد.
به همین دلیل، بنچمارکهای جدیدی مثل ResearchBench و ScienceAgentBench طراحی شدهاند.
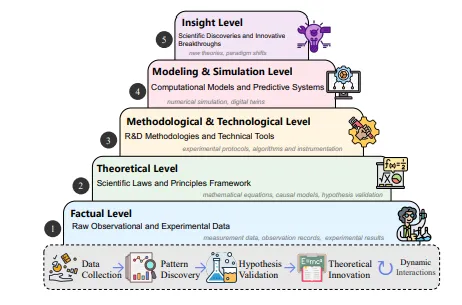
ساختار سلسلهمراتبی دانش علمی: از داده خام تا کشف بزرگ
دانش علمی تنها یک مجموعه از دادهها نیست؛ بلکه یک فرایند تکاملی و چندلایه است که از مشاهده و آزمایش ساده آغاز میشود و در نهایت به نوآوریها و کشفهای بزرگ ختم میشود. پژوهشگران این مسیر را در قالب یک ساختار سلسلهمراتبی معرفی کردهاند که پنج سطح اصلی دارد. این مقاله نگاهی ساده و آموزشی این پنج سطح را توضیح میدهد.
سطح اول: دادههای واقعی (Factual Level)
پایه و اساس دانش علمی همیشه دادههای خام است.
شامل: دادههای مشاهدهای، آزمایشگاهی و نتایج اولیه.
مثالها: ثبت دمای یک محل، مشاهدات تلسکوپی، نتایج یک آزمایش شیمی.
این دادهها ممکن است پراکنده و نامرتب باشند، اما بذر اصلی شکلگیری نظریههای علمی در همین سطح نهفته است.
سطح دوم: نظریهها و قوانین (Theoretical Level)
وقتی دادهها تحلیل میشوند، الگوهایی پدیدار میشوند که به شکل قوانین و اصول علمی در میآیند.
مثالها: قوانین حرکت نیوتن، قانون جاذبه، قوانین ترمودینامیک.
هدف: ایجاد چارچوبی نظری برای توضیح دادهها و پیشبینی پدیدههای آینده.
سطح سوم: روششناسی و فناوری (Methodological & Technological Level)
این سطح به توسعه و بهکارگیری روشها، ابزارها و فناوریهای تحقیق و توسعه (R&D) اختصاص دارد. در واقع، پلی است میان دادههای تجربی و مدلهای نظری و شبیهسازی. در این مرحله، پژوهشگران از تکنیکها و فناوریهای نو برای طراحی، اجرا و تحلیل آزمایشها استفاده میکنند تا بتوانند دادهها را به بینشهای علمی تبدیل کنند.
سطح چهارم: مدلسازی و شبیهسازی (Modeling & Simulation Level)
دانشمندان از دادهها و نظریهها برای ساخت مدلهای محاسباتی استفاده میکنند. این مدلها میتوانند پدیدههای پیچیده را شبیهسازی کنند.س
مثالها: شبیهسازی تغییرات اقلیمی، طراحی دارو با مدلهای مولکولی، مدلسازی حرکت سیارات.
مزیت: پیشبینی آینده و آزمون نظریهها بدون نیاز به آزمایش پرهزینه یا خطرناک.
سطح پنجم: بینش و کشف (Insight Level)
این بالاترین سطح دانش علمی است؛ جایی که نوآوریها و کشفهای بزرگ رخ میدهند.
مثالها: کشف ساختار DNA، شناسایی موجهای گرانشی، کشف واکسنها.
اهمیت: این سطح باعث تغییر پارادایمهای علمی و پیشرفت بزرگ بشریت میشود.
چرخه تکرارشونده علم
نکته مهم این است که علم یک مسیر خطی نیست؛ بلکه یک چرخه پویاست. این چرخه شامل مراحل زیر است:
جمعآوری داده (Data Collection)
کشف الگو (Pattern Discovery)
آزمون فرضیه (Hypothesis Validation)
نوآوری نظری (Theoretical Innovation)
تعامل پویا و شروع دوباره (Dynamic Interactions)
هر کشف جدید، خود به دادههای جدیدی منجر میشود و چرخه دوباره تکرار میشود.
نتیجهگیری کلی مقاله مدلهای زبانی بزرگ علمی
مدلهای زبانی بزرگ علمی (Sci-LLMs) در حال دگرگونی اساسی در پژوهشهای علمیاند. این مدلها از پردازش متن فراتر رفته و دادههای چندوجهی مانند تصاویر، فرمولها و دادههای آزمایشگاهی را درک میکنند. تکامل آنها از مدلهای متنی ساده تا سامانههای چندعاملی پیشرفته، مسیر خودکارسازی فرضیهسازی و تحلیل داده را هموار کرده است.
آینده Sci-LLMs وابسته به سه محور کلیدی است:
ایجاد اکوسیستمهای دادهای منسجم،
طراحی معماریهای ترکیبی یادگیری و منطق،
توسعه عوامل هوشمند پژوهشی خودمختار.

){kind=link}
خیلی مفید بود ممنونم
خیلی عالی ممنونم