
در این پست از سایت بنو قصد داریم آموزش یک مدل نمایشی از مدالیتههای مختلف را مورد بررسی قرار دهیم.
حواس چندگانه انسان
صدا، بویایی، چشایی، لامسه و بینایی – اینها پنج حسی هستند که انسان برای درک و درک جهان از آنها استفاده می کند. ما قادریم به طور یکپارچه این حواس مختلف را هنگام درک جهان ترکیب کنیم. به عنوان مثال، تماشای یک فیلم نیازمند پردازش مداوم اطلاعات دیداری و شنیداری است و ما این کار را بدون زحمت انجام می دهیم. ما بهعنوان متخصص رباتیک، بهویژه به مطالعه اینکه چگونه انسانها حس لامسه و حس بینایی ما را ترکیب میکنند، علاقهمندیم. دید و لمس هنگام انجام کارهای دستکاری که نیاز به تماس با محیط دارند، مانند بستن بطری آب یا قرار دادن اسکناس یک دلاری در یک ماشین خودکار، به ویژه مهم هستند.
بیایید بستن یک بطری آب را به عنوان مثال در نظر بگیریم. با چشمانمان میتوانیم رنگها، لبهها و اشکال موجود در صحنه را مشاهده کنیم و از آنها میتوانیم اطلاعات مربوط به وظیفه، مانند حالتها و شکل بطری آب و درپوش را استنتاج کنیم. در همین حال، حس لامسه ما بافت، فشار و نیرو را به ما میگوید، که اطلاعات مربوط به وظیفه مانند نیرویی که به بطری آب وارد میکنیم و لغزش درب بطری در دستانمان را به ما میدهد. علاوه بر این، انسانها میتوانند اطلاعات یکسانی را با استفاده از یک یا هر دو نوع حواس استنتاج کنند: حواس لامسه ما همچنین میتواند به ما اطلاعات ژست و هندسی بدهد، در حالی که حواس بینایی ما میتوانند زمان تماس ما با محیط را پیشبینی کنند.
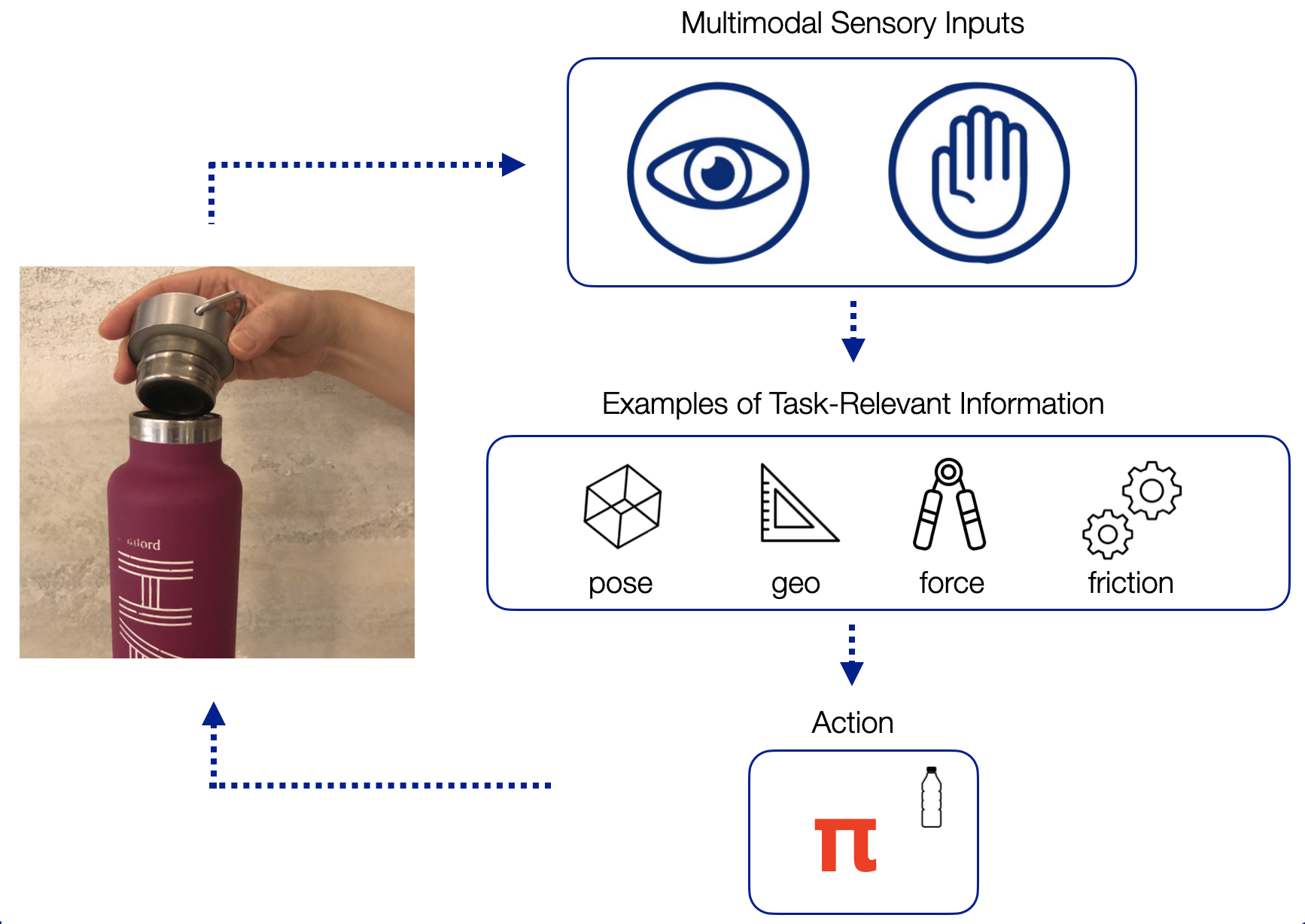
از این مشاهدات چندوجهی و ویژگیهای مرتبط با وظیفه، ما به اقدامات مناسب برای مشاهدات داده شده میرسیم تا بطری آب را با موفقیت ببندیم. با توجه به یک وظیفه جدید، مانند قرار دادن یک دلار در یک ماشین خودکار، ممکن است از همان اطلاعات مربوط به وظیفه (ژستها، شکل، نیروها و غیره) برای یادگیری یک سیاست جدید استفاده کنیم. به عبارت دیگر، ویژگیهای چندوجهی مرتبط با وظیفه خاصی وجود دارد که در انواع مختلف کارها تعمیم مییابد.
ویژگیهای یادگیری از ورودی های خام مشاهدات (مانند تصاویر RGB و دادههای نیرو/گشتاور از حسگرهایی که معمولاً در روباتهای مدرن دیده میشوند) به عنوان یادگیری نمایشی نیز شناخته میشوند. ما می خواهیم یک نمایش برای بینایی و لامسه و ترجیحاً نمایشی یاد بگیریم که بتواند این دو حس را با هم ترکیب کند. ما فرض میکنیم که اگر بتوانیم نمایشی را یاد بگیریم که ویژگیهای مرتبط با وظیفه را به تصویر میکشد، میتوانیم از همان نمایش برای کارهای مشابه با تماس غنی استفاده کنیم. به عبارت دیگر، یادگیری یک نمایش چندوجهی غنی می تواند به ما در تعمیم کمک کند.
در حالی که انسان ها به شیوه ای ذاتاً چندوجهی با جهان تعامل دارند، مشخص نیست که چگونه می توان انواع بسیار متفاوت داده ها را مستقیماً از حسگرها ترکیب کرد. تصاویر RGB از دوربین ها ابعاد بسیار بالایی دارند (اغلب در حدود 640 x 480 x 3 پیکسل). از سوی دیگر، قرائتهای سنسور نیرو/گشتاور فقط 6 بعد دارند اما در عین حال از این لحاظ پیچیدهاند که ممکن است گاهی به سرعت تغییر کنند (به عنوان مثال، زمانی که ربات به چیزی تماس ندارد، حسگر 0 نیوتن را ثبت میکند، اما میتواند به سرعت به 20 نیوتن بپرد که به محض برقراری تماس اتفاق میافتد).
ترکیب حس بینایی و لامسه
چطور میتوانیم حس بینایی و لامسه را باهم ترکیب کنیم درحالی که این دو، ویژگیهای بسیار متفاوتی دارند؟
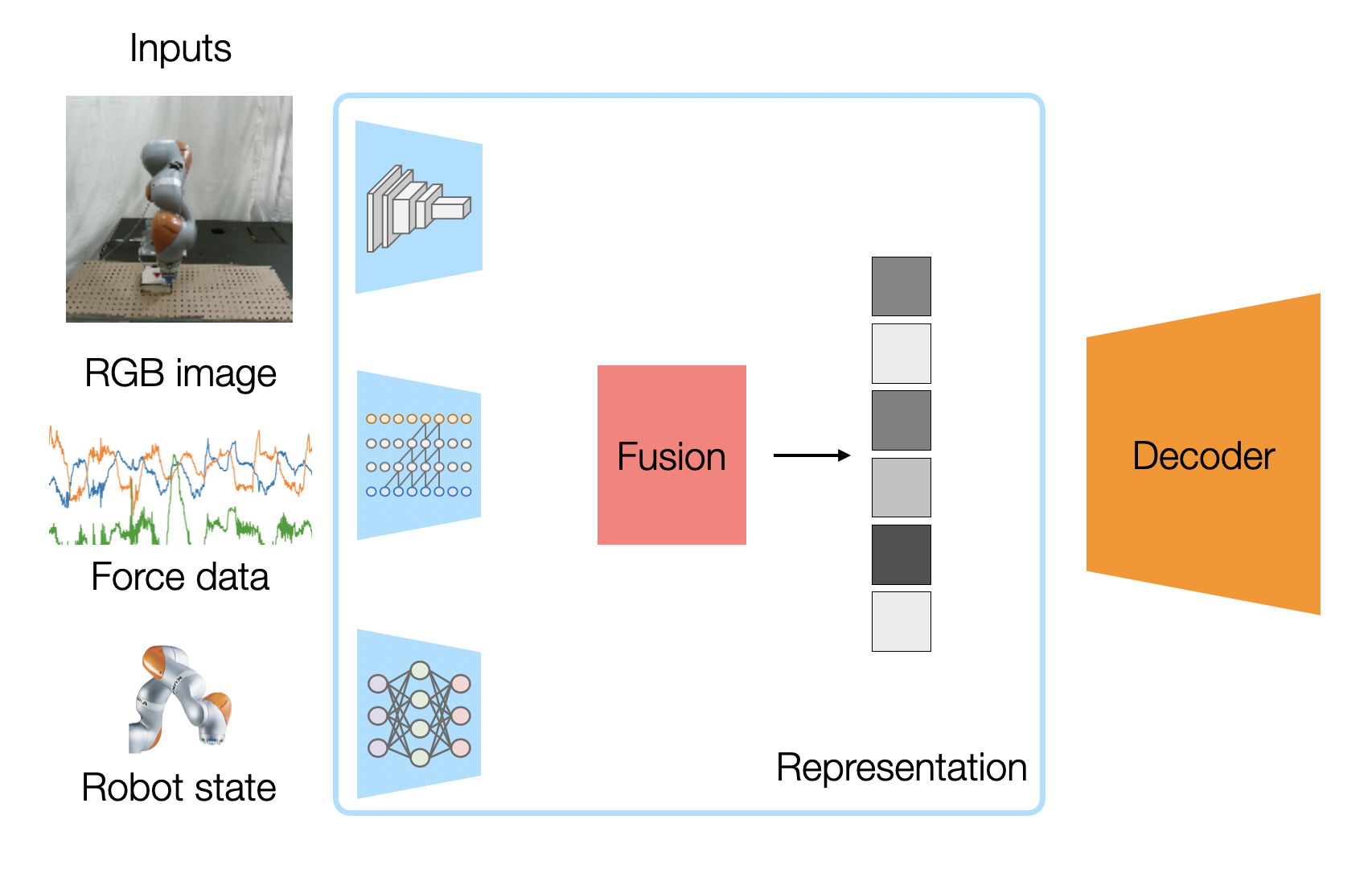
ما می توانیم از یک شبکه عصبی عمیق برای یادگیری ویژگی ها از داده های حسگر خام با ابعاد بالا استفاده کنیم. شکل بالا معماری شبکه عصبی یادگیری نمایش چندوجهی ما را نشان میدهد، که ما آموزش میدهیم تا یک نمایش برداری ترکیبی از تصاویر RGB، قرائتهای حسگر نیرو (از حسگر نیرو/گشتاور متصل به مچ) و وضعیتهای ربات (موقعیت و سرعت مچ ربات که میخ به آن متصل است) ایجاد کند.
از آنجایی که قرائتهای حسگر ما دارای ویژگیهای متفاوتی هستند، ما از معماری شبکه متفاوتی برای رمزگذاری هر مدالیته استفاده میکنیم:
- رمزگذار تصویر یک شبکه FlowNetSimple شده با یک شبکه عصبی کانولوشنال 6 لایه (CNN) است. این برای هدف self-supervised ما مفید خواهد بود.
- از آنجایی که خوانش نیروی ما یک داده سری زمانی با همبستگی زمانی است، ما از کانولوشنهای علّی(causal convolutions) برای خوانشهای نیروی خود استفاده میکنیم. این شبیه به معماری WaveNet است که نشان داده شده است که به خوبی با داده های صوتی توالی زمانی کار می کند.
- برای قرائت حسگر عمقی (proprioceptive) (موقعیت و سرعت end-effector)، آن را با لایههای کاملاً متصل (Fully Connected) رمزگذاری میکنیم، همانطور که معمولاً در رباتیک انجام میشود.
هر رمزگذار یک بردار ویژگی تولید می کند. اگر بخواهیم یک نمایش قطعی داشته باشیم، میتوانیم با به هم پیوستن آنها در یک بردار ترکیب کنیم. اگر از یک نمایش احتمالی استفاده کنیم، که در آن هر بردار ویژگی در واقع دارای یک بردار میانگین و یک بردار واریانس است (با فرض توزیعهای گاوسی)، میتوانیم توزیعهای مدالیته مختلف را با استفاده از ایده محصول کارشناسان با ضرب چگالیهای توزیعها با هم ترکیب کنیم و هر میانگین را با واریانس آن وزندهی کنیم.بردار ترکیبی حاصل، نمایش چندوجهی ما است.
چگونه ویژگی های چندوجهی را بدون برچسب زدن دستی یاد بگیریم؟
رمزگذارهای مدالیته ما نزدیک به نیم میلیون پارامتر قابل یادگیری دارند که برای آموزش با یادگیری نظارت شده به مقادیر زیادی داده برچسبگذاری شده نیاز دارد. برچسب گذاری دستی داده ها بسیار پرهزینه و گران قیمت خواهد بود. با این حال، میتوانیم اهداف آموزشی را طراحی کنیم که برچسبهای آنها به طور خودکار در طول جمعآوری دادهها تولید میشوند. به عبارت دیگر، ما می توانیم رمزگذارها را با استفاده از یادگیری خود نظارتی آموزش دهیم. تصور کنید که بخواهید 1000 ساعت ویدیوی یک ربات در حال انجام یک کار را حاشیه نویسی کنید یا سعی کنید به صورت دستی وضعیت اشیا را برچسب گذاری کنید. به طور شهودی، شما ترجیح میدهید فقط یک قاعده بنویسید مانند « نظارت بر نیروی وارد بر بازوی ربات را انجام بده و جفت حالت و عمل را زمانی که خوانشهای نیرویی بیش از حد بالا است، برچسبگذاری کن »، بهجای اینکه هر فریم را یکبهیک بررسی کنید که ربات کی با جعبه در تماس است. ما کاری مشابه را انجام می دهیم، با برچسبگذاری الگوریتمی دادههایی که از اجراهای ربات جمعآوری میکنیم.
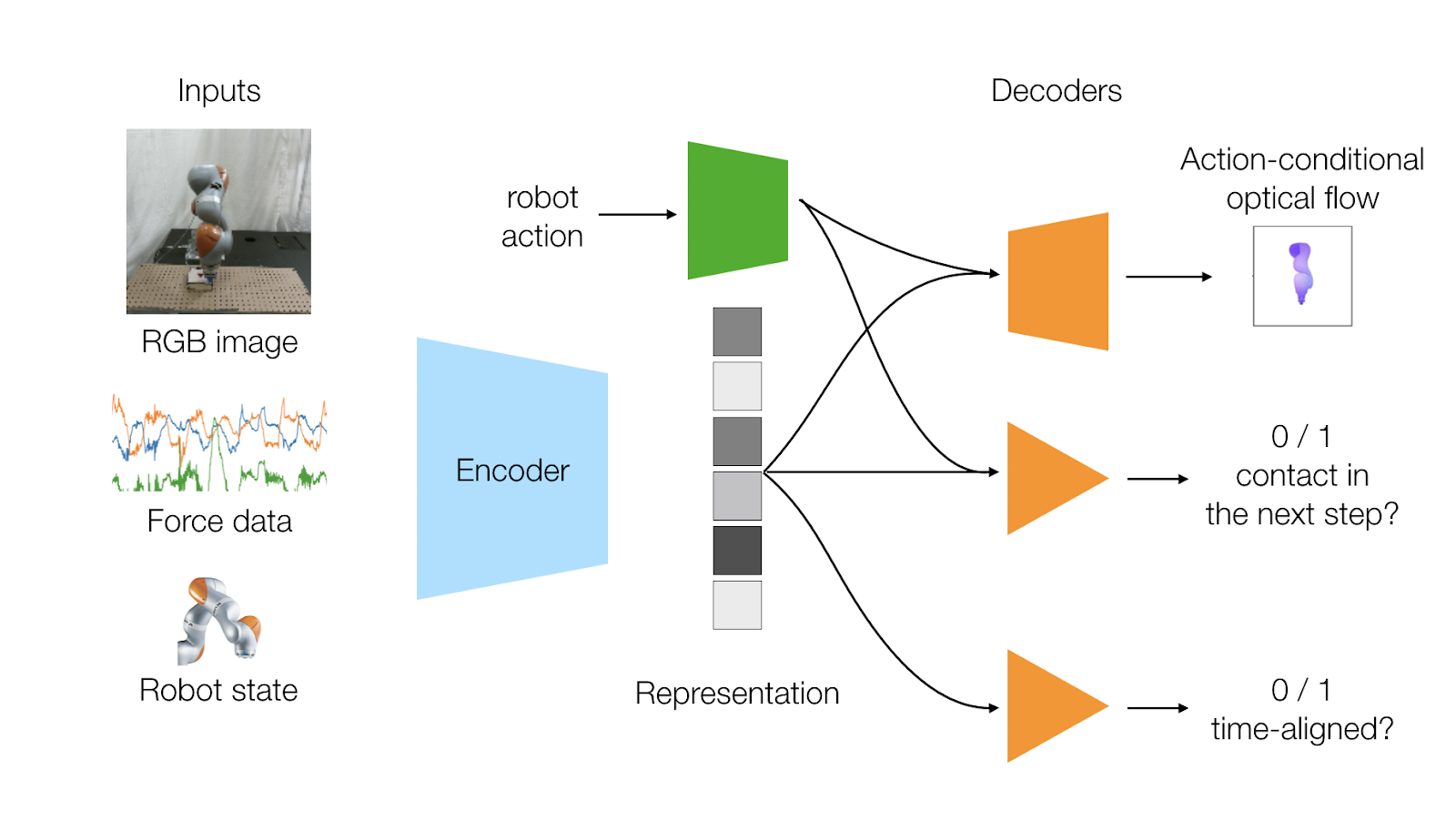
ما دو هدف یادگیری را طراحی میکنیم که دینامیک مدالیتههای حسگر را در بر بگیرد:
- پیشبینی جریان بصری ربات که ناشی از عمل است
- پیشبینی اینکه آیا ربات با توجه به عمل با محیط تماس برقرار میکند یا خیر.
از آنجایی که معمولاً ما هندسه، سینماتیک و mesheهای ربات را میدانیم، برچسبگذاریهای واقعی جریان بصری میتوانند بهطور خودکار با توجه به موقعیتهای مفصلی و سینماتیک ربات تولید شوند. پیشبینی تماس نیز میتواند بهطور خودکار با جستجوی افزایشها در دادههای حسگر نیرو تولید شود.
هدف یادگیری خودنظارتی آخر ما تلاش میکند تا همبستگی زمانی قفل شده بین دو مدالیته حسگر مختلف بینایی و لمس را به تصویر بکشد و رابطه بین آنها را یاد بگیرد. وقتی ربات با محیط تماس میگیرد، یک دوربین تعامل و حسگر نیرو همزمان تماس را ثبت میکند. بنابراین، این هدف پیشبینی میکند که آیا مدالیتههای ورودی ما همزمان هستند یا نه. در طول آموزش، ما به شبکهمان دادههای همزمان و همچنین دادههای حسگر که بهطور تصادفی جابجا شده، میدهیم. شبکه ما باید بتواند از نمایش ما پیشبینی کند که آیا ورودیها همراستا هستند یا نه.
برای آموزش مدل خود، ۱۰۰ هزار داده در ۹۰ دقیقه جمع آوری کردیم. این کار با انجام عملهای تصادفی توسط ربات و همچنین انجام عملهای از پیش تعریف شدهای که قرار دادن میخها در سوراخ را تشویق میکرد، انجام شد. این عملها شامل جمعآوری برچسبهای خود نظارتی به روش توضیح داده شده در بالا است. سپس با استفاده از الگوریتم نزول گرادیان تصادفی استاندارد، نمایش خود را آموزش میدهیم و این آموزش برای ۲۰ دور انجام میشود.
چگونه بفهمیم که نمایش چندوجهی خوبی داریم؟
یک نمایش خوب باید:
- به ما امکان یادگیری یک سیاست را بدهد که بتواند یک وظیفه manipulation غنی از تماس (مثل وظیفه وارد کردن میخ) را به شیوهای کارآمد انجام دهد.
- بتواند در نمونههای مختلف کار تعمیم یابد (مثلاً اشکال مختلف میخ برای وارد کردن میخ)
- به ما اجازه دهد که یک سیاست را یاد بگیریم که در برابر نویزهای حسگر، مختلکنندههای خارجی و مکانهای هدف مختلف مقاوم باشد.
برای مطالعه نحوه یادگیری این نمایش چندوجهی، از یک وظیفه درج میخ به عنوان یک تنظیم آزمایشی استفاده می کنیم. ورودی های چندوجهی ما تصویر خام RGB، قرائت نیرو از حسگر نیرو/گشتاور، و موقعیت و سرعت end-effector است. بر خلاف کارهای کلاسیک در وارد کردن میخ با دقت بالا که به دانش قبلی از اشکال میخ نیاز دارند، ما سیاستها را برای اشکال مختلف بهطور مستقیم از تصاویر خام RGB و قرائت های حسگر نیرو/گشتاور یاد خواهیم گرفت.مهمتر از آن، ما می خواهیم یک نمایش از یک شکل میخ یاد بگیریم، و ببینیم که آیا این نمایش می تواند به اشکال دیده نشده جدید تعمیم یابد یا خیر.
یادگیری سیاست
ما می خواهیم ربات بتواند سیاست ها را مستقیماً از تعاملات خود با محیط بیاموزد. در اینجا، ما به الگوریتمهای یادگیری تقویتی عمیق (RL) روی میآوریم، که عامل ها را قادر میسازد از آزمون و خطا و یک تابع پاداش یاد بگیرند. یادگیری تقویتی عمیق پیشرفت های زیادی را در انجام بازی های ویدیویی، گرفتن اشیاء توسط ربات و حل مکعب های روبیک نشان داده است. به طور خاص، ما از Trust Region Optimization، یک الگوریتم RL روی سیاست، و یک پاداش متراکم که ربات را به سمت سوراخ برای وارد کردن میخ راهنمایی میکند.
یک بار که نمایش را یاد گرفتیم، آن را بهطور مستقیم به یک سیاست RL میدهیم. و ما توانستهایم کار وارد کردن میخ برای اشکال مختلف میخ را در حدود ۵ ساعت از ورودیهای حسی خام یاد بگیریم.
این ربات است زمانی که برای اولین بار شروع به یادگیری کار میکند.

حدود ۱۰۰ ایپاک که گذشت (که ۱.۵ ساعت میشود)، ربات شروع به لمس جعبه میکند

و در 5 ساعت، ربات میتوناند بهطور مطمئن میخ گرد، مثلثی و همچنین میخ نیمدایرهای وارد کند.

ارزیابی نمایش ما
ما ارزیابی میکنیم که نمایش ما چقدر خوب ورودیهای چندوجهی ما را پوشش میدهد، با آزمایش اینکه نمایش چگونه به نمونههای وظیفه جدید تعمیم داده میشود، سیاست ما با نمایش به عنوان ورودی وضعیت چقدر مقاوم است و چگونه مودهای مختلف (یا عدم وجود آنها) بر یادگیری نمایش تأثیر میگذارند.
تعمیم نمایش ما
ما پتانسیل انتقال سیاستها و نمایندگیهای آموختهشده را به دو شکل جدید که قبلاً در آموزش نمایش و سیاست مشاهده نشدهاند، یعنی میخ ششضلعی و میخ مربعی، بررسی میکنیم. برای انتقال سیاست، ما مدل نمایش و سیاستی که برای میله مثلثی آموزش دیده است را میگیریم و با میله مربعی جدید که دیده نشده، اجرا میکنیم. همانطور که در گیف زیر میبینید، وقتی که انتقال سیاست را انجام میدهیم، نرخ موفقیت ما از ۹۲٪ به ۶۲٪ کاهش مییابد. این نشان میدهد که سیاستی که برای یک هندسه میلهای آموخته شده، لزوماً به هندسه میلهای جدید منتقل نمیشود.
عملکرد انتقال بهتر را می توان با استفاده از مدل نمایش آموزش داده شده بر روی میخ مثلثی، و آموزش سیاست جدید برای میخ شش ضلعی جدید به دست آورد. همانطور که در گیف مشاهده می شود، وقتی نمایش چندوجهی را منتقل می کنیم، نرخ درج میخ ما دوباره به 92% می رسد. حتی اگر سیاستهای آموختهشده به اشکال جدید منتقل نشوند، نشان میدهیم که نمایش چندوجهی ما از بازخورد بصری و لمسی میتواند به نمونههای جدید وظیفه منتقل شود. نمایندگی ما به اشکال جدید میخ های دیدهنشده تعمیم مییابد و اطلاعات مربوط به وظیفه را در سراسر نمونههای وظیفه جمعآوری میکند.

استحکام سیاست
ما نشان دادیم که سیاست ما در برابر نویزهای حسگرهای نیرو/گشتاور و دوربین مقاوم است.
اختلال حسگر نیرو: وقتی که به حسگر نیرو/گشتاور ضربه میزنیم، گاهی اوقات این حسگر ربات را فریب میدهد که فکر کند با محیط تماس دارد. اما سیاست هنوز هم قادر است از این اختلالات و نویزها بهبود یابد.

پوشش دوربین: وقتی که بهطور متناوب دوربین را پوشش میدهیم بعد از اینکه ربات قبلاً با محیط تماس برقرار کرده است. سیاست همچنان قادر است از وضعیتهای ربات، خوانشهای نیرو و تصاویر پوشیده شده، سوراخ را پیدا کند.

حرکت هدف: ما میتوانیم جعبه را به یک مکان جدید منتقل کنیم که ربات هرگز در طول آموزش آن را ندیده است و ربات ما همچنان قادر به تکمیل درج میخ است.

نیروهای خارجی: ما همچنین میتوانیم ربات را مختل کنیم و نیروهای خارجی را مستقیماً بر روی آن اعمال کنیم و هنوز هم قادر است عمل درج را تمام کند.

همچنین توجه داشته باشید که ما سیاستهای خود را بر روی دو ربات مختلف، ربات نارنجی KUKA IIWA و ربات سفید Franka Panda اجرا میکنیم که نشان میدهد روش ما بر روی رباتهای مختلف کار میکند.
مطالعه حذف
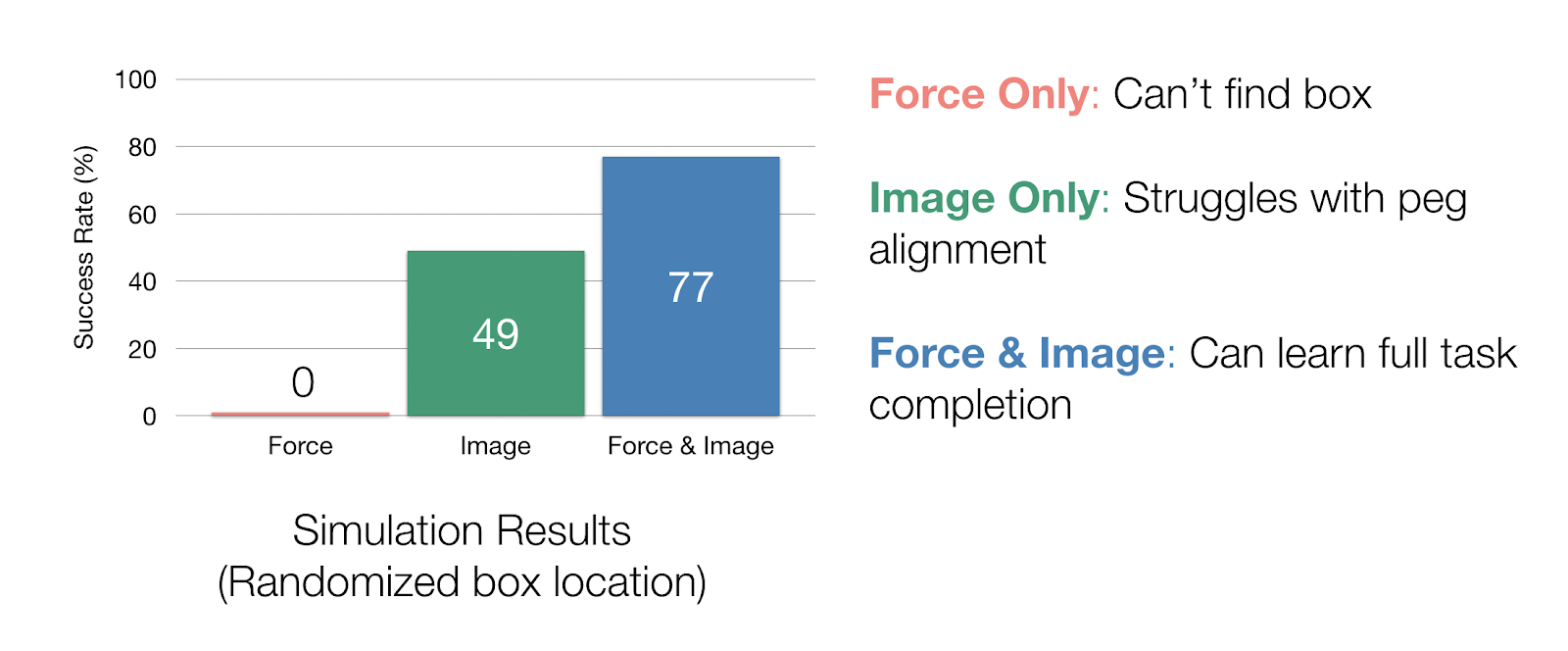
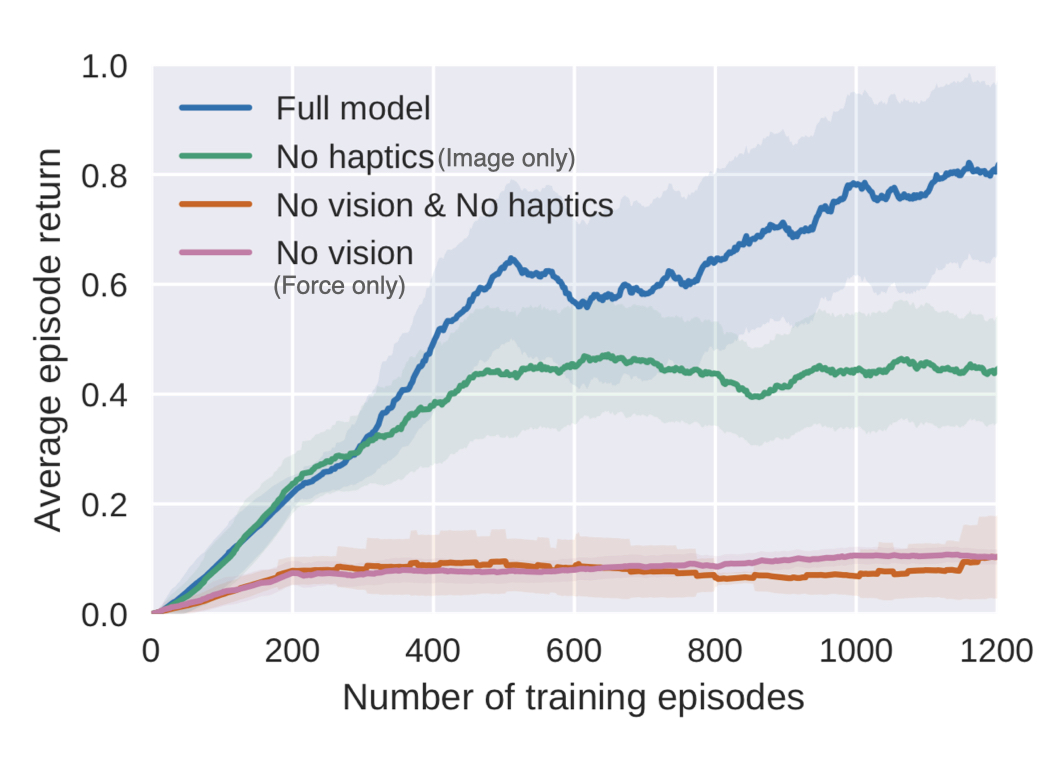
برای مطالعه تأثیرات اینکه چگونه مدالیتههای مختلف بر نمایش تأثیر میگذارند، ما یک مطالعه حذف در شبیهسازی انجام دادیم. در آزمایشهای شبیهسازی خود که در آن مکان جعبه را تصادفی میکنیم، میتوانیم نحوه استفاده از هر حسگر را با حذف کامل یک مدالیتی در طول نمایش و آموزش سیلست مطالعه کنیم. اگر فقط دادههای نیرو را داشته باشیم، سیاست ما نمیتواند جعبه را پیدا کند. با تنها دادههای تصویری، ما به نرخ موفقیت ۴۹٪ در انجام وظیفه میرسیم، اما سیاست ما واقعاً با همسو کردن میخ با سوراخ مشکل دارد، زیرا دوربین نمیتواند این حرکات دقیق کوچک را ثبت کند. با هر دو ورودی نیرو و تصویر، نرخ تکمیل کار ما در شبیه سازی تا 77 درصد می رسد.
منحنی های یادگیری همچنین نشان می دهد که Full Model و مدل فقط تصویر (بدون Haptics) بازدهی مشابهی در ابتدای آموزش دارند.. همانطور که آموزش ادامه مییابد و ربات یاد میگیرد که به جعبه نزدیکتر شود، زمانی که Full Model بتواند سریعتر و قویتر یاد بگیرد که چگونه میخ را با بازخورد بصری و نیرو وارد کند، بازده شروع به واگرایی میکند.جای تعجب نیست که یادگیری یک نمایش با چندین مدالیته، یادگیری سیاست را بهبود میبخشد، اما نتیجه ما همچنین نشان میدهد که نمایش و سیاست ما از همه مدالیتهها برای وظایف غنی از تماس استفاده میکنند.
خلاصه
به عنوان یک نمای کلی از روش ما، دادههای خود برچسبگذاری شده را از طریق خود نظارتی جمعآوری میکنیم، که حدود ۹۰ دقیقه طول میکشد تا ۱۰۰ هزار نقطه داده جمعآوری شود. ما میتوانیم نمایشی از این دادهها بیاموزیم، که حدود 24 ساعت آموزش روی یک GPU طول میکشد، اما کاملاً آفلاین انجام میشود. پس از آن، میتوانید سیاستهای جدیدی را از همان نمایش یاد بگیرید، که فقط 5 ساعت آموزش واقعی ربات طول میکشد. این روش را می توان بر روی ربات های مختلف یا برای انواع مختلف وظایف انجام داد.
در اینجا برخی از نکات کلیدی این کار آورده شده است:
- اولین مورد این است که نظارت بر خود، به ویژه دینامیک و پیشبینی همزمانی زمانی اهداف غنی را برای آموزش یک مدل نمایشی از مدالیتههای مختلف به ما بدهد.
- دوم، نمایشی که همزمانی مدالیتههای ما و دینامیکهای پیشرو را به تصویر میکشد، میتواند در میان نمونههای مختلف وظیفه تعمیم یابد (برای مثال، اشکال میخ و مکان حفره) و نسبت به نویز سنسور مقاوم است. این نشان میدهد که ویژگیهای هر مدالیته و رابطه بین آنها در نمونههای مختلف وظایف غنی از تماس مفید است.
- در نهایت، آزمایشهای ما نشان میدهند که یادگیری نمایش چندمدالیته منجر به کارایی یادگیری و پایداری سیاست میشود.
برای کارهای آینده، ما میخواهیم روش ما بتواند فراتر از یک خانواده وظایف، به کارهای کاملاً متفاوت و غنی از تماس تعمیم دهد (مانند خرد کردن سبزیجات، تعویض لامپ، قرار دادن دوشاخه برق). برای انجام این کار، ممکن است نیاز به استفاده از روشهای بیشتری داشته باشیم، مانند ترکیب دما، صدا، یا حسگرهای لمسی، و همچنین پیدا کردن الگوریتمهایی که بتوانند به ما سازگاریهای سریعی با وظایف جدید بدهند
برای اطلاعات بیشتر درباره این پروژه، میتوانید از مقاله منتشر شده آنها بازدید کنید.
اگه به مطالعه در مورد هوش مصنوعی و کاربرد های آن در حوزه رباتیک علاقه مند هستید میتوانید پست قبلی سایت بنو ذر رابطه با رباتهای خودبهبود دهنده را مشاهده کنید!
این پست برگرفته از جدیدترین اخبار دانشگاه استنفورد میباشد. منبع


{kind=link}
بدون دیدگاه