ترکیب RAG و Fine-Tuning : نبرد دو روش برای آموزش مدلهای زبانی بزرگ
چگونه مایکروسافت با ترکیب این دو رویکرد، هوش مصنوعی را به یاری کشاورزی آورد
مایکروسافت و ترکیب RAG و Fine-Tuning ،تا امروز بیشتر عاملهای هوشمند با دادههای انسانی یا پاداشهای صریح آموزش میدیدند. اما هر دو مسیر چالشهای خاص خود را دارند:
چرا RAG و Fine-Tuning مهماند؟
در دنیای هوش مصنوعی، بهویژه در مدلهای زبانی بزرگ مثل GPT-4 و Llama2، دو روش اصلی برای اضافه کردن دانش جدید وجود دارد:
RAG (تولید مبتنی بر بازیابی) – مدل پاسخها را با استفاده از دادههای بیرونی بهصورت لحظهای تولید میکند.
Fine-Tuning (تنظیم دقیق) – مدل با دادههای جدید آموزش میبیند تا دانش را در خودش ذخیره کند.
مایکروسافت در این پژوهش بهصورت علمی و عملی این دو روش را مقایسه کرده و نشان داده هرکدام چه مزایا و محدودیتهایی دارند، بهویژه در صنعت کشاورزی. برای مفهوم بهتر هوش مصنوعی در ریاضیات را مطالعه کنید.
استفاده از هوش مصنوعی در کشاورزی
کشاورزی یکی از مهمترین و در عین حال کمتر دیجیتالیشدهترین صنایع دنیاست.
درحالیکه پزشکی و مالی سالهاست از هوش مصنوعی بهره میبرند، کشاورزی هنوز بهصورت سنتی اداره میشود.
مایکروسافت تصمیم گرفت بررسی کند که اگر بتوانیم هوش مصنوعی را به یک «دستیار هوشمند کشاورز» تبدیل کنیم چه اتفاقی میافتد؟
برای مثال:
کشاورزان در ایالتهای مختلف آمریکا سؤالهای مشابهی میپرسند، اما پاسخ آنها وابسته به منطقه است.
مثل: بهترین زمان کاشت درخت سیب در آرکانزاس چه زمانی است ؟در جورجیا چطور؟
GPT-4 پاسخ کلی میدهد («پاییز و بهار زمان خوبی برای کاشت است»)،
اما کارشناس محلی جواب دقیقتری دارد («در جورجیا اواخر اکتبر و در آرکانزاس فوریه بهترین زمان است»).
هدف مایکروسافت این بود که با ترکیب RAG و Fine-Tuning، مدل بتواند مثل آن کارشناس محلی پاسخ دهد.

پایپلاین (Pipeline) پیشنهادی مایکروسافت
مایکروسافت یک سیستم چندمرحلهای طراحی کرد تا بتواند دادههای تخصصی را وارد مدل کند.
این سیستم از پنج مرحله تشکیل میشود:
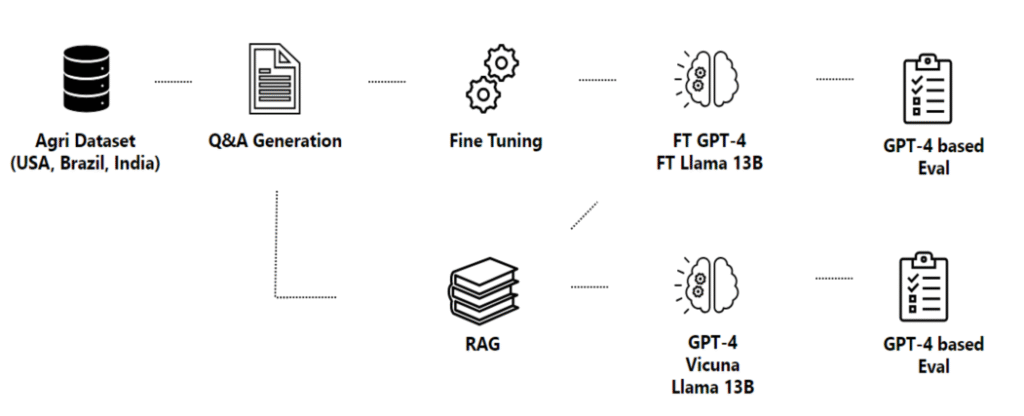
1.جمعآوری دادههای تخصصی
دادهها از منابع معتبر جمعآوری شدند:
ایالات متحده: وزارت کشاورزی آمریکا (USDA) و دانشگاههای Land-Grant
برزیل: پایگاه دادهٔ Embrapa شامل ۵۰۰ پرسش و پاسخ تخصصی
هند: پورتالهای KVK و Vikaspedia که بیش از ۱۰۰هزار سؤال واقعی کشاورزان دارند
این دادهها شامل گزارشهای علمی، دستورالعملهای زراعی، آزمونهای تخصصی، و حتی پرسشهای محلی از کشاورزان واقعی بودند.
2.استخراج داده از PDFها
چون بیشتر دادهها در قالب PDF بودند (و PDF برای نمایش ساخته شده، نه تحلیل)، استخراج اطلاعات از آنها کار سادهای نبود.
تیم مایکروسافت از ابزار GROBID استفاده کرد تا ساختار متن، جداول و تصاویر را جدا کند و خروجی ساختاریافتهای در قالب JSON بسازد.
این کار باعث شد مدل بتواند بفهمد کدام بخش مربوط به عنوان است، کدام جدول است و کدام توضیح.
3.تولید سؤالها و پاسخها (Q&A Generation)
در این مرحله، مدل GPT-4 با دادههای استخراجشده تغذیه شد و به کمک فریمورک Guidance، سؤالهای دقیق و واقعگرایانه تولید کرد.
مثلاً:”چگونه تغییرات اقلیمی بر تولید گندم در شمال غرب آمریکا اثر می گذارد؟”
“نقش کود بوراکس در تغذیه ی مرکبات چیست؟”
سپس برای هر سؤال، پاسخهای اولیه با استفاده از RAG تولید شدند — یعنی مدل ابتدا اطلاعات را جستوجو و سپس پاسخ را نوشت.
4. استفاده از RAG برای غنیسازی پاسخها
RAG ترکیبی از «جستوجو» و «تولید» است.
مایکروسافت برای این کار از سیستم FAISS برای جستوجوی برداری (Vector Search) استفاده کرد.
هر سؤال بهصورت یک embedding برداری تبدیل میشد، و مدل مرتبطترین پاراگرافها از پایگاه داده را بازیابی میکرد.
این روش کمک کرد تا پاسخها واقعیتر و کمتر «ساختگی» باشند.
5.آموزش مدل با Fine-Tuning
در پایان، مدلها با دادههای پرسشوپاسخ بهدستآمده آموزش دیدند.
از تکنیک LoRA (Low-Rank Adaptation) برای کاهش هزینه استفاده شد تا مدل بتواند با دادههای جدید بدون از دست دادن دانش قبلی بهروزرسانی شود.
این فرایند روی چندین GPU قدرتمند (H100 و A100) انجام شد.مقاله ی مربوط به این مبحث را از دست ندهید.

نتایج کلیدی پژوهش
نتایج این آزمایشها واقعاً چشمگیر بودند:
افزایش دقت ۶ درصدی با Fine-Tuning نسبت به مدل اولیه
افزایش ۵ درصدی دیگر هنگام ترکیب Fine-Tuning با RAG
شباهت پاسخها با پاسخ متخصصان از ۴۷٪ به ۷۲٪ رسید
مدل GPT-4 در عملکرد بهترین بود، ولی هزینهاش بالاتر بود
به بیان سادهتر:
مدلهای بومیسازیشده با دادههای واقعی کشاورزی، هم دقیقتر پاسخ دادند و هم بهتر توانستند شرایط منطقهای را در نظر بگیرند.
مقایسه نهایی دو روش
| ویژگی | RAG | Fine-Tuning |
|---|---|---|
| نوع یادگیری | جستوجوی بلادرنگ در دادههای خارجی | ذخیرهی دانش درون مدل |
| سرعت اجرا | سریع و انعطافپذیر | نیازمند آموزش زمانبر |
| هزینه | پایین | بالا |
| دقت پاسخها | وابسته به منبع داده | بسیار بالا و پایدار |
| مناسب برای | دادههای پویا و زنده (اخبار، قوانین) | دادههای تخصصی و ثابت (پزشکی، کشاورزی) |
این فرایند روی چندین GPU قدرتمند (H100 و A100) انجام شد.
ترکیب RAG و Fine-Tuning – بهترین راهحل
مایکروسافت پیشنهاد میکند این دو روش را ترکیب کنیم:
RAG برای دسترسی به دانش جدید و زنده
Fine-Tuning برای یادگیری عمیق و دقت بالا
نتیجه چنین ترکیبی، یک مدل دولایه است:
لایهی دانش پایدار (پایهی علمی و تخصصی)
لایهی دانش پویا (اطلاعات تازه و لحظهای)
به این ترتیب، مدل میتواند مثل یک انسان متخصص رفتار کند:
دانش پایهاش را از سالها تجربه دارد، اما هر روز خودش را با دادههای جدید بهروزرسانی میکند.
آیندهی کاربردها
این تحقیق فقط دربارهی کشاورزی نیست.
همین پایپلاین را میتوان برای صنایع دیگر هم پیاده کرد:
پزشکی: مدلهایی که بر اساس دادههای محلی بیمارستانها Fine-Tuned شدهاند و از مقالات جدید پزشکی با RAG تغذیه میشوند.
حقوق: دستیارهای وکیل که از قوانین محلی یاد گرفتهاند و قوانین روز را از RAG بازیابی میکنند.
آموزش: معلمهای هوش مصنوعی که براساس کتابهای درسی خاص هر کشور آموزش دیدهاند.

جمعبندی نهایی مایکروسافت و ترکیب RAG و Fine-Tuning
مایکروسافت با این پژوهش نشان داد که آیندهی هوش مصنوعی در صنایع تخصصی، در ترکیب هوشمندانهی RAG و Fine-Tuning است.
مدلهایی که هم میتوانند یاد بگیرند، هم جستوجو کنند، و هم پاسخ دقیق، محلی و قابل اعتماد بدهند.
در دنیایی که دادهها هر لحظه تغییر میکنند،
این ترکیب میتواند هستهی نسل بعدی AI Copilotها باشد — دستیارهایی که واقعاً مثل انسان فکر میکنند و عمل میکنند.

{kind=link}
بدون دیدگاه