
چگونه هوش مصنوعی کوچک TRM، پازل های سخت حل می کند؟
مدلهای زبانی بزرگ (LLMs) مانند GPT یا Gemini ۲.۵ Pro در بسیاری از وظایف زبانی عملکردی فوقالعاده دارند. اما وقتی پای پازلها، منطق و استدلالهای گامبهگام به میان میآید دچار ضعف میشوند.دلیل این ضعف، روش تولید پاسخ بهصورت خودکار و زنجیرهای (auto-regressive) است. اگر تنها یک اشتباه کوچک در تولید یک توکن رخ دهد، این اشتباه میتواند کل پاسخ را بیاعتبار کند.روش سنتی برای تقویت استدلال در این مدلها، استفاده از «زنجیره افکار» (Chain of Thought) است که در آن مدل پاسخ را مرحلهبهمرحله تولید میکند. با این حال، این روش پرهزینه و اغلب ناپایدار است.در مقابل، هوش مصنوعی کوچک TRM از یک شبکهی عصبی بسیار کوچک دولایه استفاده میکند و از طریق یک فرایند بازگشتی، پاسخ خود را بهتدریج اصلاح میکند. این فرآیند شبیه به انسانی است که بارها به یک مسئله فکر میکند و هر بار پاسخ خود را بهبود میبخشد.
در این میان، گروهی از پژوهشگران در شرکت Samsung SAIL Montréal رویکردی متفاوت ارائه کردند که در عین سادگی، قدرتی چشمگیر دارد.
هوش مصنوعی کوچک TRM و پایه بازگشتی آن
پژوهشگران شرکت Samsung SAIL Montréal مدلی به نام Tiny Recursive Model (TRM) هوش مصنوعی کوچک TRM ساختهاند. این مدل با تنها دو لایه و حدود هفت میلیون پارامتر، میتواند در برخی وظایف استدلالی، عملکردی بهتر از مدلهایی با صدها میلیارد پارامتر داشته باشد. ایدهی اصلی TRM، «استدلال بازگشتی» است. مدل پاسخ اولیهای تولید میکند و سپس در یک حلقه، آن را بارها بازبینی و بهبود میبخشد. این رویکرد نهتنها به دادههای عظیم نیاز ندارد، بلکه با منابع محدود نیز به نتایج قابلتوجهی میرسد.
برای مفهوم بیشتر این مقاله هوش محاسبات تکاملی را مطالعه کنید.
تفاوت با مدل HRM
پیش از TRM، مدلی به نام Hierarchical Reasoning Model (HRM) وجود داشت که از دو شبکهی عصبی در دو سطح برای استدلال سلسلهمراتبی استفاده میکرد. HRM در حل پازلهای پیچیده مانند سودوکو موفق عمل میکرد، اما پیادهسازی آن دشوار بود. این مدل بر مفاهیم زیستی مبهم و قضایای ریاضی پیچیده تکیه داشت و آموزش آن پرهزینه و کند بود. هوش مصنوعی کوچک TRM با حذف این پیچیدگیها و استفاده از یک شبکهی کوچک و بازگشتی، به همان اهداف با کارایی بالاتر و سادگی بیشتر دست مییابد.
برای مفهوم بیشتر مقاله مروری جامع بر روشهای فاین تیونینگ در مدلهای زبانی بزرگ را از دست ندهید.
ساختار TRM چگونه است؟
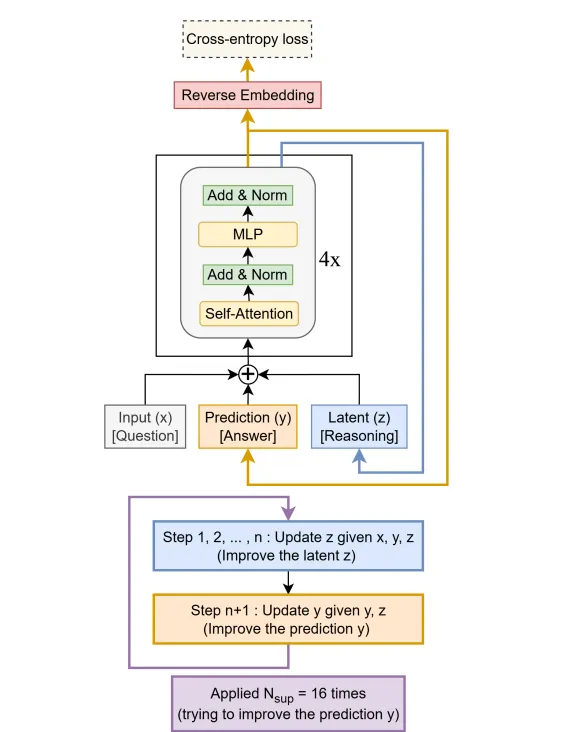
ساختار هوش مصنوعی کوچک TRM تنها بر سه مؤلفه کلیدی استوار است:
ورودی مسئله (x)
پاسخ فعلی (y)
ویژگی پنهان استدلال (z)
مدل ابتدا پاسخ اولیه (y) را تولید میکند. سپس در یک حلقه بازگشتی، این سه مؤلفه را ترکیب و بارها بهروزرسانی میکند تا پاسخ را بهتدریج اصلاح نماید. این فرایند به مدل اجازه میدهد اشتباهات خود را تشخیص دهد و بدون نیاز به داده جدید، در یک فرآیند “تفکر درونی”، پاسخ را به واقعیت نزدیکتر کند.
اما راز موفقیت TRM در چیست ؟
راز موفقیت هوش مصنوعی کوچک TRM در سادگی آن نهفته است. این مدل برخلاف HRM به قضیهی نقطه ثابت یا توجیهات پیچیده بیولوژیکی نیاز ندارد. همچنین بهجای استفاده از دو شبکه، تنها از یک شبکه کوچک بهره میبرد. TRM فرآیند توقف خودکار (Adaptive Computation Time) را با یک محاسبه ساده احتمالاتی انجام میدهد و تنها با یک پاس (forward pass) میآموزد که چه زمانی یادگیری را متوقف کند. پژوهشگران با استفاده از تکنیک «میانگین نمایی وزنها» (EMA)، پایداری آموزش را افزایش و خطر بیشبرازش (overfitting) را کاهش دادهاند.
از نظر مفهومی، دو ویژگی کلیدی مدل، پاسخ فعلی (y) و استدلال پنهان (z) هستند. (y) خروجی نهایی مدل است و (z) حافظه درونی مسیر تفکر آن را تشکیل میدهد. ترکیب این دو، به TRM امکان میدهد روند استدلال خود را مانند ذهن انسان حفظ کند و بر اساس تجربیات قبلی تصمیمگیری نماید. حذف هر یک از این دو، باعث از دست رفتن بخشی از منطق یا حافظه مدل میشود.
نتایج آزمایشها شگفتانگیز است
پژوهشگران به نتیجه جالبی رسیدند: هرچه مدل سادهتر باشد، عملکرد بهتری دارد. افزودن لایهها و پارامترهای بیشتر تنها منجر به بیشبرازش و افت دقت میشود. دو لایه برای ایجاد تعادل بین عمق و تعمیمپذیری کافی است. در برخی آزمایشها، نسخه دو لایه TRM حتی از نسخههای چهار لایه یا شبکههای مبتنی بر Self-Attention نیز بهتر عمل کرد. این یافته تایید میکند که گاهی سادگی، بهترین شکل هوشمندی است.
مقاله ی جالب MCP – پروتکل زمینه مدل چیست؟ را از دست ندهید.
پژوهشگران TRM را روی چهار چالش کلاسیک آزمودند و نتایج زیر را در مقایسه با HRM و مدلهای زبانی بزرگ (LLMs) به دست آوردند:
| وظیفه | HRM (27M) | TRM (7M) | مدلهای زبانی بزرگ |
|---|---|---|---|
| Sudoku-Extreme | ۵۵٪ | 🟢 ۸۷٪ | ۰٪ |
| Maze-Hard | ۷۵٪ | 🟢 ۸۵٪ | ۰٪ |
| ARC-AGI-1 | ۴۰٪ | 🟢 ۴۵٪ | تا ۳۷٪ |
| ARC-AGI-2 | ۵٪ | 🟢 ۸٪ | تا ۴.۹٪ |
اهمیت این کشف تنها در بهبود دقت نیست، بلکه در چشمانداز جدیدی است که برای آینده هوش مصنوعی ترسیم میکند. هوش مصنوعی کوچک TRM ثابت میکند که برای دستیابی به هوش استدلالی، لزوماً به مدلهای عظیم و پرهزینه نیاز نیست. شبکههای کوچک و بازگشتی میتوانند با هزینهای بسیار کمتر و روی سختافزارهای معمولی، عملکردی مشابه یا بهتر ارائه دهند. این امر گامی بزرگ به سوی هوش مصنوعی سبک، قابل اعتماد و خوداستدلالگر است — هوشی که نه بر قدرت محاسباتی، بلکه بر روش تفکر تکیه دارد.
در نهایت، پژوهشگران مقاله نتیجه میگیرند که در دنیای هوش مصنوعی نیز «کمتر، بیشتر است». Tiny Recursive Model نشان داد که میتوان بدون نیاز به مدلهای غولآسا و میلیاردپارامتری، به استدلال منطقی، خودبازبینی و یادگیری مؤثر دست یافت. این دستاورد شاید مسیری تازه بهسوی هوش مصنوعی عمومی (AGI) بگشاید؛ جایی که هوش نه از اندازه، بلکه از عمق اندیشه میآید.
سخن نهایی
پژوهشگران در نهایت نتیجه میگیرند که در دنیای هوش مصنوعی نیز «کمتر، بیشتر است». Tiny Recursive Model نشان داد که میتوان بدون نیاز به مدلهای غولآسا، به استدلال منطقی، خودبازبینی و یادگیری مؤثر دست یافت. این دستاورد مسیری تازه به سوی هوش مصنوعی عمومی (AGI) میگشاید؛ مسیری که در آن هوش از عمق اندیشه میجوشد، نه از مقیاس بزرگ.
سادگی و بازگشتهای هوشمندانه میتوانند جایگزین مقیاس بزرگ و پرهزینه شوند. این رویکرد، راهی نو برای طراحی مدلهای کوچک، قابلاعتماد و عمومیتر در زمینه استدلال باز کرده است و شاید پایهای برای نسل بعدی هوش مصنوعی خوداستدلالگر باشد.

){kind=link}
بدون دیدگاه